DeepFaceLab620稳定版使用过程详解!
网站上的小白入门系列教程是基于2019.3.13的版本而编写,有部分内容已经发生了变化。而目前比较稳定的版本为620,这个版本保持了很长一段时间,并没有发现什么大问题,用着挺好。所以我决定针对这个版本从新写一个使用教程。(哭,写了几天项目作者开始疯狂更新版本….不过没关系620还是值得拥有!)
这个教程主要是为了把一些更新的内容囊括进来,不会像小白入门那么细致,但是我会尽量写的通俗易懂。
1. DeepFaceLab的安装
软件安装部分可以参考之前的教程,是一模一样的,核心要点只有一个:更新驱动(鲁大师, 驱动精灵,去英伟达官网下载都可以)。
2.DeepFaceLab小版本的选择

另外一个需要提前说明的问题是,关于小版本的选择的问题。
DeepFaceLab每一次发布都是4个小版本。
- 10.1AVX: N卡推荐这个,AVX值得是CPU的指令集,一般新的CPU都支持这个指令集。
- 10.1SSE: 如果你是N卡,但是CPU不支持AVX,那么可以选择这个版本。
- 9.2SSE: 这个版本CUDA是9.2, 其他同上。如果没有特殊原因还是建议使用10.1版
- OpenCLSSE: 针对AMD显卡和CPU用户。
3.DeepFaceLab的基本流程。
DeepFaceLab虽然更新了很多版本,但是基本流程没有变。
主要是还是一下几个步骤:
- 提取脸图
- 训练模型
- 图片转换
- 合成视频
4.DeepFaceLab H64使用举例。
DeepFaceLab软件自带了5个模型,H64,H128,DF,LIAEF128,SAE 。 每个模型都有自己的特色,这里不展开说。
其中H64是一个经典模型,几乎所有的AI换脸软件都支持这个模型,我还是以这个模型为例来演示。
2) extract images from video data_src (SRC视频转图片)
3.2) extract images from video data_dst FULL FPS(DST视频转图片)
4) data_src extract faces S3FD best GPU (提取SRC人脸图片)
5) data_dst extract faces S3FD best GPU (提取DST人脸图片)
6) train H64(训练模型,不会自动结束,耗时久)
7) convert H64(图片换脸)
8) converted to mp4 (将图片合成视频)
所有步骤中记住一个点,如果停住了就按回车,有的时候需要按很多次。只有第六步没法按回车结束的。
第六步关闭的方法有两种,
一种直接把窗口关掉,右上角xx,大家都懂的。
另一种,在预览窗口回车(竟然还是回车…)
5.DeepFaceLab 步骤详解。
开始前,先说下我的基本配置和Workspace。
我的配置配置
系统:window10 ,
DFL: DeepFacelab10.1AVx 620,
CUDA: CUDA10.1 ,
显卡: GTX 1070 8G
Workspace介绍
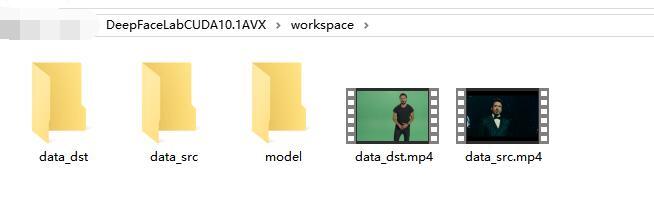
workspace翻译过来就是工作空间,很多编程工具和设计类软件都有这个概念。这个目录就是用来放置素材和结果文件的。
软件自带了这个文件夹,文件夹里面有两个视频,三个目录。
分别是:data_dst , data_src ,model , data_dst.mp4,data_src.mp4.
在运行软件的过程中还会生成图片和视频。这些文件和目录是干嘛的我会在下面的详细步骤中一一说明。
这里重点说一下这两个视频,src视频可以称为源视频,dst视频称为目标视频。
换脸的过程就是把src视频中的人脸放到dst视频的身体上。
下面开始具体的操作。
2) extract images from video data_src
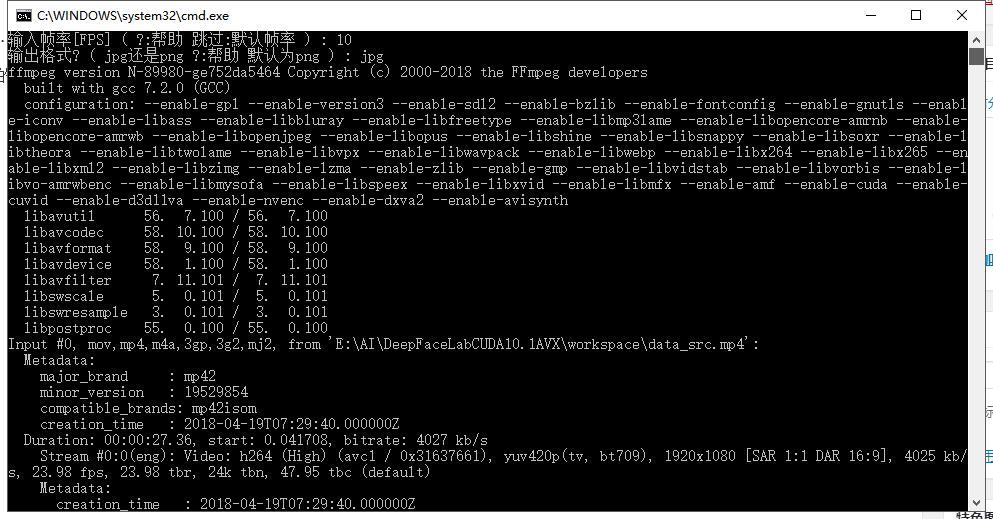
双击以上脚本,跳出一个黑色窗口,你需要输入帧率(推荐:10),选择输出格式(推荐jpg) 。 输入一个,按一下回车。
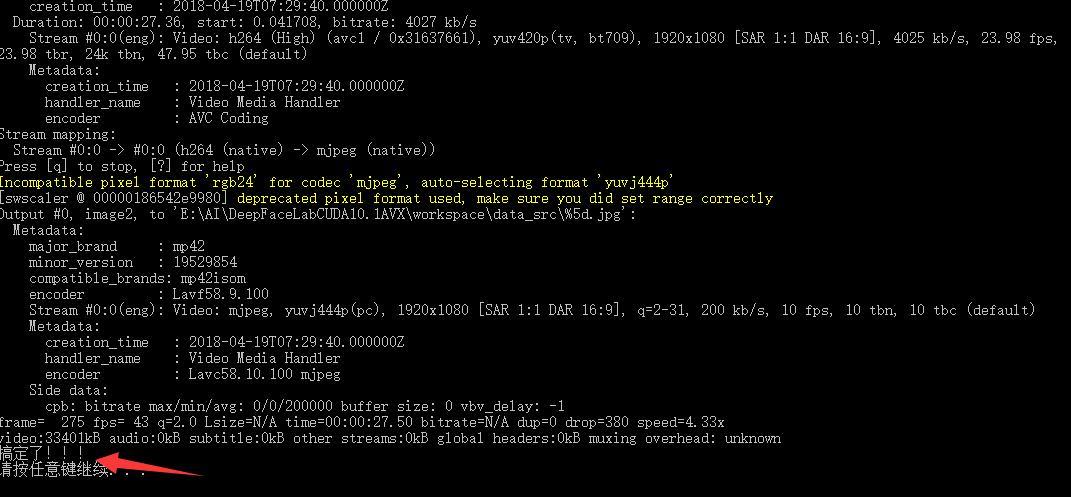
稍等片刻即可完成,英文版会有Done的提示,中文版看各自的翻译了,完成按任意键即可退出。执行成功,workspace/data_src下面会产生很多图片,如下图:
3.2) extract images from video data_dst FULL FPS(DST视频转图片)
这个步骤和上面的非常类似,只是这一次操作的是data_dst.mp4这个视频。
这一步中只要要输入jpg回车即可,等待一小段时间后,出现完成提示,即可关闭窗口。
此时,workspace/data_dst中出现了好多图片。
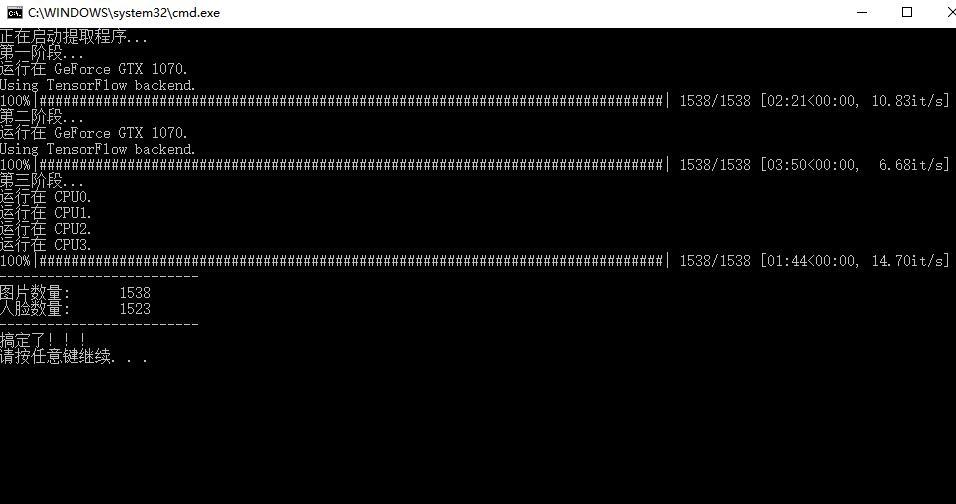
4) data_src extract faces S3FD best GPU
这一步骤的操作是,从图片中提取人脸,也叫切脸。主要分三个阶段,第一阶段和第二阶段是主要使用GPU,第三阶段使用CPU。
注意:第一次使用的时候第一阶段会停留 比较常的时间,这是正常现象!
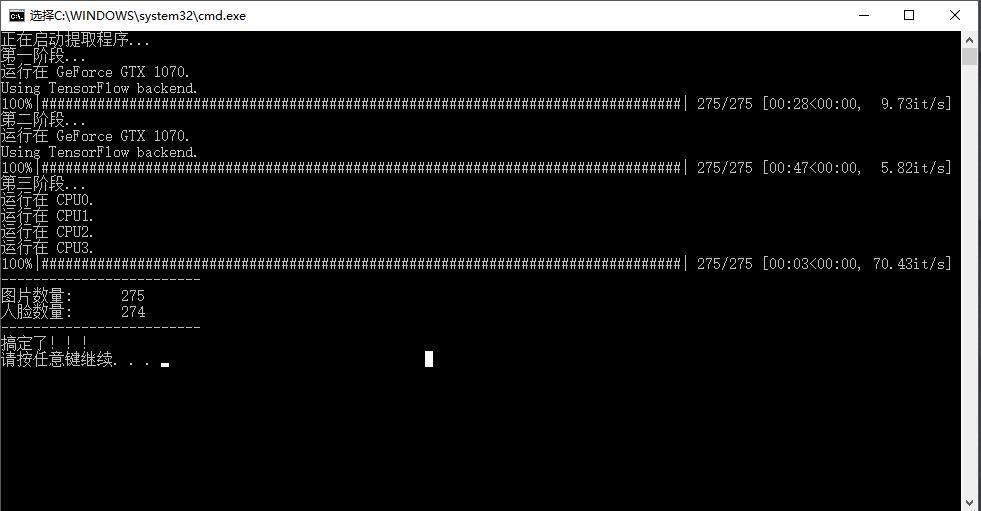
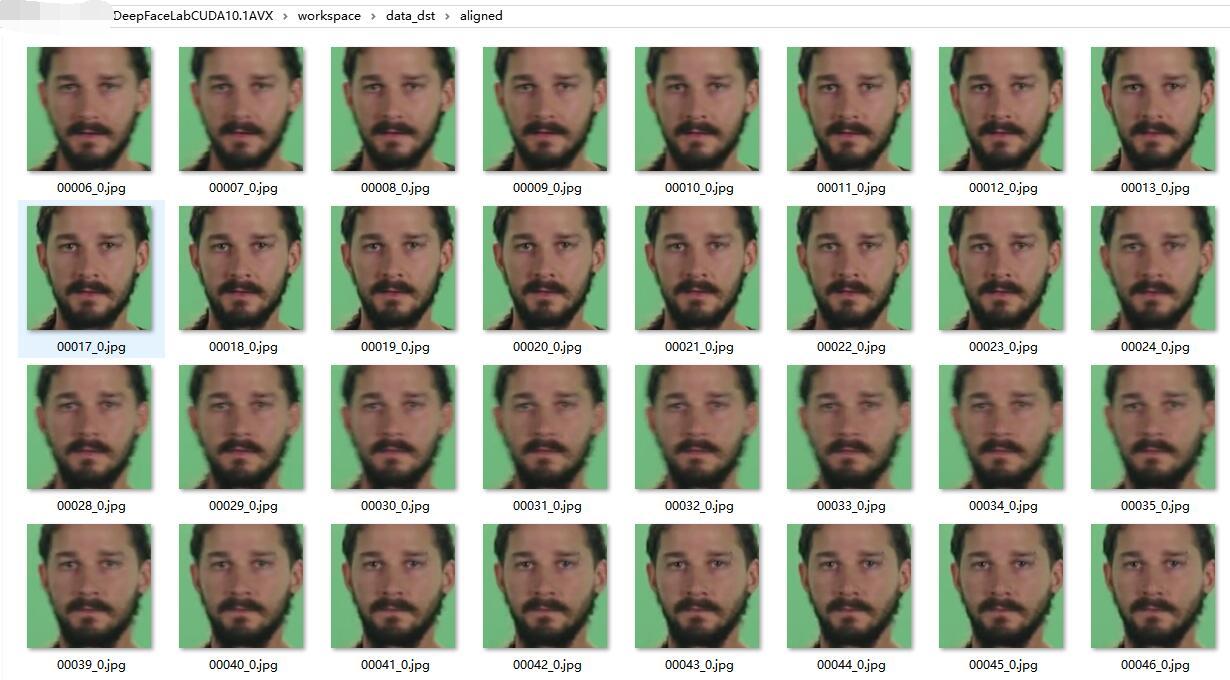
操作成功后会显示处理了多少图片,提取到多少头像。同时,workspace/data_src/aligned 下面会产生很多头像。这个头像是非常关键的。
这一个环节需要注意两个点:
1. 如果驱动太老会报错,
2. 第一次运行这个步骤会特别慢,中途会有类似卡死的错觉,你只要等等即可。
5) data_dst extract faces S3FD best GPU
这一步和上一步一样的操作,只是对象不一样而已。
6) train H64.bat
这是一个核心步骤,并且是最特殊一步,他不会自动结束。第一次启动会提示你输入若干个参数,作为新手,可以直接回车回车回车,这样就会使用默认参数启动模型。
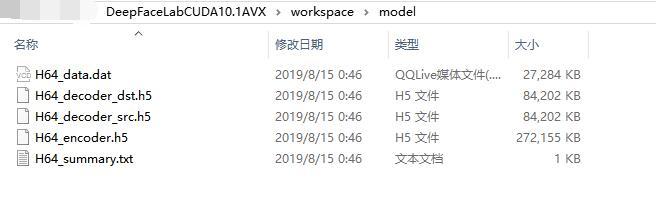
模型启动后,workspace/model 目录下会出现5个文,这就是模型文件。
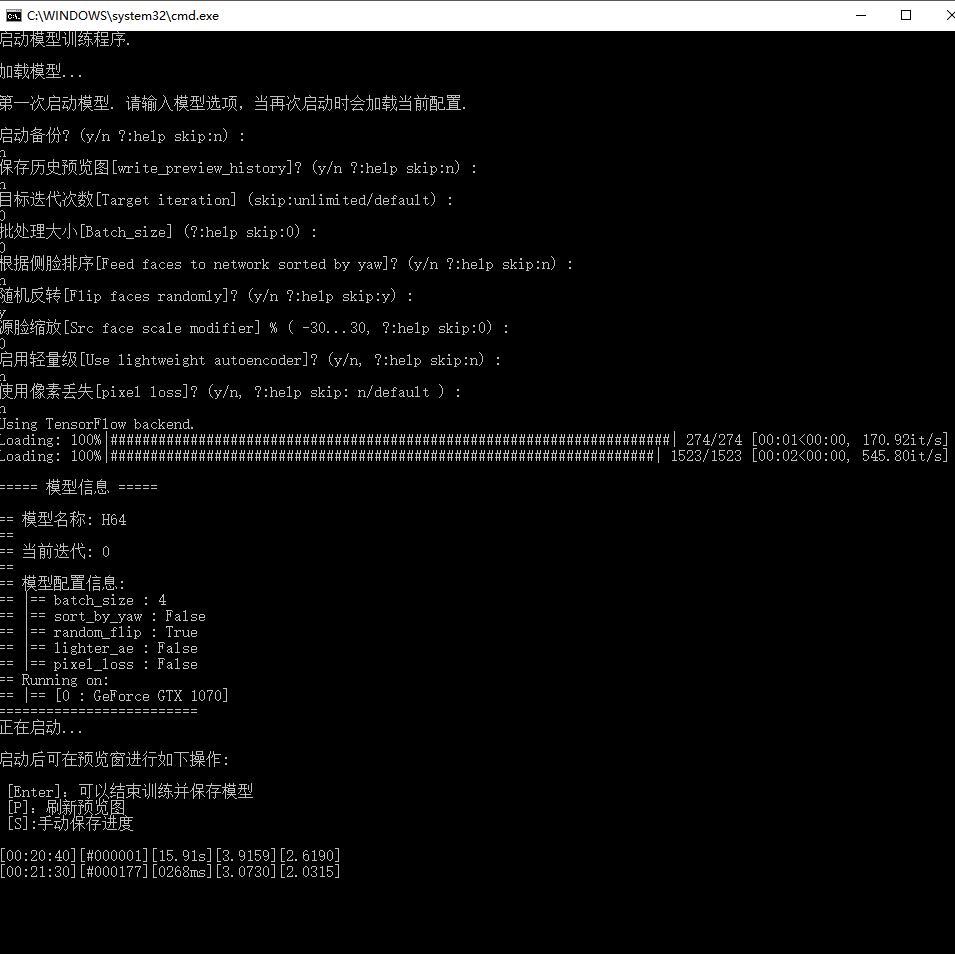
参数配置完成后,软件会加载第四步和第五部提取出来的头像,用来训练模型。模型启动后,底部会出现时间和一些跳动数字。同时跳出一个新的窗口。上面会有很多头像。
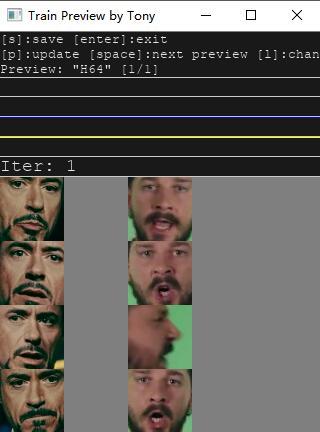
刚开始如上,只有两列头像,其他区域为灰色。
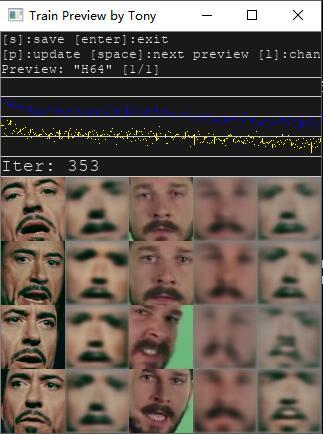
在这个窗口上按P或者等待十几分钟之后预览图会刷新,第三列和四五列出现头像。随着时间的推移,这些头像会从模糊变清晰。
因为这个步骤不会主动停止,所以让很多新手产生了一个困惑:我到底应该在什么时候关闭? 关闭后还能继续么?
首先,关闭后是可以继续的,软件会定时自动保存进度,下次用同样的方式启动后会自动加载之前的进度和配置。
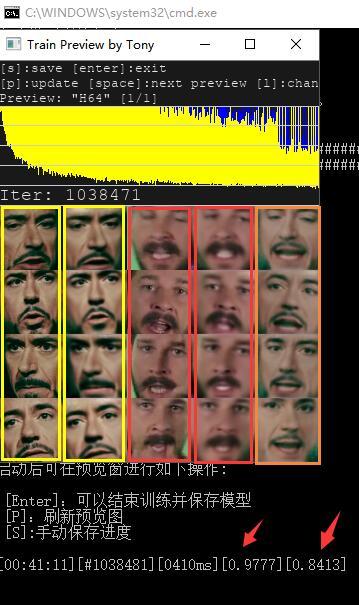
其次,你可以通过两个依据判断是否可以停止这个步骤了。
第一:直接看图片,你认为第一列和第二列,第三列和第四列,已经够清晰了。
第二:看黑色窗口中跳动的数字,最后两个数字接近0.2 就差不多了。
7) convert H64
这个步骤主要实现图片换脸。参数是比较多的。新手可以一路回车到底,全部默认。
参数配置完成后,转换程序就会开始共工作,同时以百分比的形式显示转换进度。
转换过程中,workspace/data_dst/merged 下面会生成图片。这个图片就是已经换完脸的图片。
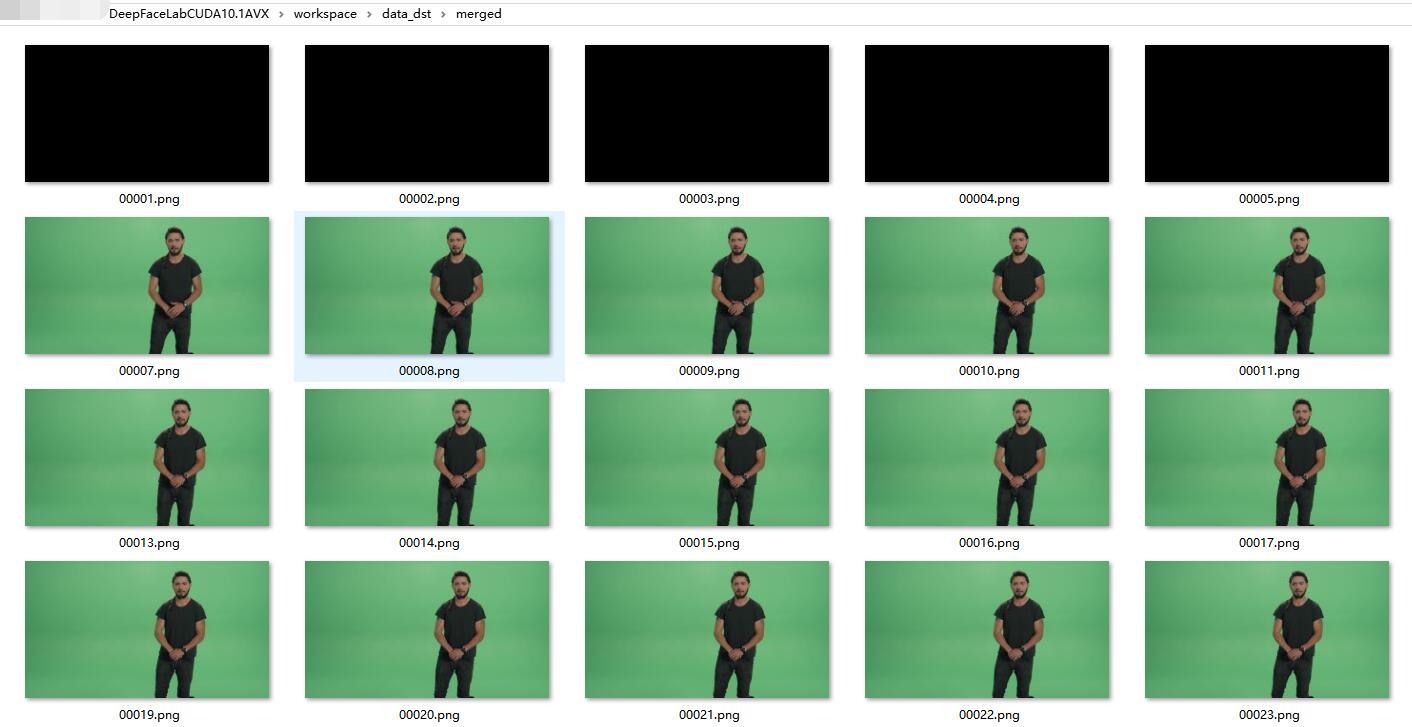
从中选一张,打开一看。托尼的脸已经被放到变形金刚男主角的身体上。因为我的训练时间非常短,所以效果一般。如果需要好的效果,可以增长训练时间。

8) converted to mp4
这一步主要是将已经换好脸的图片合成成视频,一般是合成mp4格式的视频。
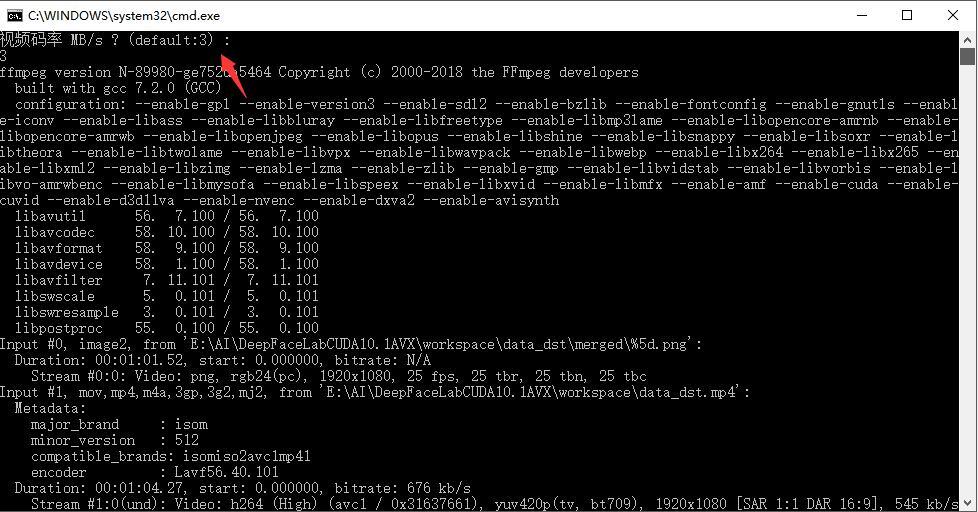
合成视频的时候需要输入一个视频码率,原版默认值为16,这样会导致合成是视频非常大。
这里推荐输入3,在保证清晰度的情况下,文件也不会很大。
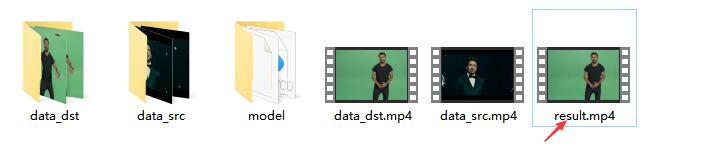
结束后,workspace下面会出现一个result.mp4的文件。这样整个换脸过程就结束了。

打开视频即可播放,和Fakeapp相比,DFL优点很多,比如清晰度更高,合成的视频带音轨,无水印。
写文章也是挺累的,边操作边截图,写完还得改错别字,能不能写个提纲,让AI来完成呢?


请问620版本在哪下载
你好,请问哪里可以下载deepface呢?
群文件:672316851 ,公众号:托尼是塔克(发送 dfl或openface),或者 github.都可以滴。
公众号怎么是中国邮政,而且里面什么都没有啊
(⊙o⊙)…,不会吧。微信公众号:托尼是塔克 没错啊!
一楼托尼斯塔克 你字打错了,是另一个公众号
尴尬尴尬尴尬,改了改了改了
托尼是塔克 ,是是是是是,不是斯不是斯不是斯
现在换脸软件都是只能用英伟达显卡吗?
AMD卡不行吗?
opencl可以支持amd卡,但是支持的不好是很好。就看你运气了。
您好朋友:我想知道你的显卡配置,还有训练迭代100多万次的耗时是多久
可以大概算一下:假设一个迭代800ms, 100万=1000000×0.8=800000s = 222小时 没算错的话差不多十天十夜。 这是一次成功的时间,如果你需要不停调优,那么时间xN
大神我问你一下 一个迭代的时间可以设置吗还是看配置的啊?
src一定要是视频吗,如果是是的话可以用非mp4格式的视频吗?
src可以用图片吗,如果可以怎么命名呢
可以是图片,推荐用视频,可以不是mp4格式,只要名字是data_src.xxx即可。
如果有多张图片该如何命名?
有几个问题
1不同版本的模型是通用的吗? 还说模型需要重新训练?
2原先src切的脸,训练了一段时间,发现有的图片不好,后来又切了一部分脸放在aligned里面把原来的部分图片删了,拿之前训练的模型会用新素材优化之前的模型吗?
麻烦解答一下,谢谢大佬
1.不同版本基本是通用的!但是也对看时机跨度长不长,SAE好多版本是不兼容的。
2. 换素材后会用新的素材训练,但是效果不会立竿见影,需要训练一段时间或者很长一段时间才能把新的特征训练进去,而旧的特征很难被剃除。
感谢大佬。
上个星期第一次训练模型。素材不会挑。
准备先用这个模型不断调优剔除素材之后,再重新训练一个好的模型
第二步的时候,显示错误:
Could not open file : C:\Program Files\DeepFaceLab\DeepFaceLabCUDA10.1AVX\workspace\data_src\00001.jpg
av_interleaved_write_frame(): I/O error
发现这个路径下根本没有图片文件生成,楼主怎么解决??
你这个是读写有问题:要么没权限,要么路径有问题。
这是没有c盘写入权限,这个问题我刚解决
你可以百度一下怎么获取c盘读写权限
rtx2070是不是要用另一个版本,rtx版有什么优势吗
rtx 可以用AVX版的。没啥特别!
你好 首先感谢博主的资料整理 很受用.
我想问 如果只是把A图片上的脸 换到B 图片上
可以用deepfacelab吗?
可以,但是没法直接把A换到B。需要练一个模型,然后就可以换单张图片或者视频都可以。
Error: integer division or modulo by zero
请问博主大大这个是什么错误呢?
额,我搜索了一下,发现是dst的视频不够清晰没有提取到人脸
这个一般是缺少图片,检查一下,dst和src下相应的位置图片是否都存在!
请问一部20分钟的视频要训练多久呢?
你要理解,软件的使用实际上是分训练模型和使用模型。 训练模型需要很久(几天,几十天),而使用模型就比较快了(几分钟几十分钟)
你好,按顺序执行到第8步:8) converted to mp4的时候,
显示reference_file not found.
请问是什么原因引起的。
已解决,源视频的文件名改了。
你好,在运行extract face时蓝屏是什么原因呢?跟配置有关系吗?(data_dst extract faces S3FD best GPU)
蓝屏是和你电脑有关吧,没听说用这个软件蓝屏啊。
哦哦,谢谢啦!我之前用笔记本跑的,我回去换个台式机跑一下看看!
你好請問
我現在用AMD顯卡在跑,看著你不吝分享的文章 使用上也都沒問題很順利的再算圖。
但長期來看是否還是入手用N卡為佳呢?
我原本是想升級AMD Radeon VII的
恩,跑这个肯定N卡比较好。很多深度学习的软件都是支持N卡,但是不支持A卡。
两部视频一定要只能出现目标人和替换人吗? 如果有其他人就用不了了吗??
能用啊。
error:OOM when allocating tensor with shape [16384,1024]and type float on/job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU 0 bfc
配置不够!把BS调低,或者更换其他低配模型。
我这点击)4没了反应为啥
第一次,会加载比较久。后面就好了!
请问AMD显卡怎么办
用OpenCl版