DeepFaceLab小白入门(5):训练换脸模型!
训练模型,是换脸过程中最重要的一部分,也是耗时最长的一部分。很多人会问到底需要多少时间?有人会告诉你看loss值到0.02以下就可以了。我会告诉你,不要看什么数值,看预览窗口的人脸。看第二列是否和第一列一样清晰,看最后一列是否清晰,如果答案是“是”,那么恭喜你可以进入下一个环节了。

这个环节主要包括5个文件,每个文件代表一种模型,你只需选择一种即可。目前用的比较多的是,H64,H128,SAE 。
如果你玩这个软件,建议选着H64,出效果快,参数简单。
如果你需要更高的清晰度可选H128
如果你需要自定义更多参数选SAE。
6) train H64.bat
这个步骤虽然是最重要的,但是操作其实非常简单,比如你使用H64模型。只需双击文件。

双击文件文件之后一路回车,当跳出带头像的预览窗口就代表已经开始训练。刚开始训练的时候,第二列和第四列是空的,什么都没有,随着时间的推移会出现模糊的头像,继续训练头像会越来越清晰。
6) train H128.bat

这是H128,点击后出现的预览图明显比H64要大很多,这也是他们唯一的区别。
6) train SAE.bat

这是SAE的效果图。默认SAE的头像是128×128,等同于H128。 但是SAE的参数会更多。
下面说说模型训练环节常见的几个概念
Batch_size
这是一个深度学习中最常见的数字,也是每个模型必备参数。这个值到底取多少没有标准,默认为4,你可以用的值为2的n次方,比如2,4,8,16,32,64,128。一个普遍的常识是,数字大的会比小的效果好,loss收敛更快,震荡区域更小,但是对于机器配置的要求也越高。主要是对显存需求变大,一般4G显存最高只能16,继续提高会报OOM错误。
Epoch
这又是一个深度学习概念,讲的是训练完所有素材消耗的时间,最新版本这个名词改成了iteration 。 这么一改可能会让人有点混乱,但是你无需过多关注。你可以简单的认为是训练的次数。这个数值越大训练次数越多,效果越好。 而[1046ms] 这个数字越低,代表你电脑的配置越好,训练模型需要的时间更短。
LOSS
这TM又是一个深度学习的概念,反正就是越低越好。但是不要看绝对值,要看趋势,这个值慢慢降低,对应的预览图会越来越清晰,当降到一定数值(不一定是0.02或者0.01)后就很难在降低。
History

在开始训练的时候Write preview history 输入Y之后,workspace\model\h64_history下面就会保存各个阶段的预览图。这个图很直观的展现了你这个模型的进化过程。
对于train这个训练环节,你只要看最直观的预览图即可,其他都是浮云,浮云,浮云。
训练结束之后!!!
我们就可以进入真正的换脸环节了:脸部替换以及合成视频!
DeepFaceLab入门系列文章:
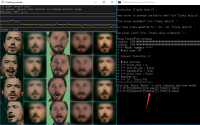

把整个脸型也一起换了的是哪个模型 试了下SAE也只是换脸而已 头部不变
所有模型都只换脸部区域,不换脸型的!
选H128 开始训练后也出了预览窗口人脸 但训练几分钟后 就memorry error 麻烦问下咋回事
显存不够,检查下时候已经开了一个训练,或者打开了其他消耗显存的软件。
为什么我的训练不出来浏览窗口啊?
有跳出一堆异常的字母了,没有的话,等带。有的话根据提示在网站上找答案。
大佬,SAE和H128区别在哪啊?有人说 SAE的效果更好,是吗?
H128是一个比较传统的模型,SAE是一个有众多参数可以调的模型。 新手用H64或者H128比较简单,如果你想要调出更好的想效果可以使用SAE。 SAE默认的像素和H128是相同的,但是最高可以调到256。 SAE严格来说并不是一个独立的模型,通过参数配置可以配出H64,H128,DF等模型。
为什么我1060的显卡在训练模型的时候显示显存只有2g啊
这个问题不止一个人问,因为我没用过1060也不是非常肯定。 不过你可以采取如下措施。 1.观察模型是否能正常训练,如果能,那么这只是一个提示错误。2.如果影响运行,建议重新安装驱动,精确安装可以参考CUDA10.1的安装。
站长 你好,我没有添加SRC视频,未进行 2) extract images from video data_src (SRC视频转图片);直接把网上保存的图片放到workspace/data_src下,然后进行面部图片提取,后面几步进行的都没有问题,但最后却未合成MP4文件,请问是怎么回事?不是说可以用图片的吗?
convert H64时候出现错误
Error: [Errno 32] Broken pipe
Traceback (most recent call last):
File “E:\DeepFaceLabTorrent\_internal\bin\DeepFaceLab\mainscripts\Converter.py”, line 250, in main
debug = debug ).process()
File “E:\DeepFaceLabTorrent\_internal\bin\DeepFaceLab\utils\SubprocessorBase.py”, line 100, in process
p.start()
File “multiprocessing\process.py”, line 105, in start
File “multiprocessing\context.py”, line 223, in _Popen
File “multiprocessing\context.py”, line 322, in _Popen
File “multiprocessing\popen_spawn_win32.py”, line 65, in __init__
File “multiprocessing\reduction.py”, line 60, in dump
BrokenPipeError: [Errno 32] Broken pipe
内核没装好
我手动换好脸后不管输出什么格式都是刚进去就闪退
为什么进行到 train H128.bat这个步骤 ,一路回车下来,最下面的:Starting.Press “Enter”to stop training and save model.就不动了~
这个是对的啊,等待一段时间就会出现跳动数字,并且出现预览界面,就证明在训练了。
我也是这个页面,卡了一个小时了还是不动,之前也出现过,后来重启就好了,现在一直卡,删了model重新运行就提示ValueError: No training data provided.
跳出数字了,但是一直都没有女出现预览界面,等了20多分钟了
解决了吗 同样的问题。。
请问一下SAE运行的话对电脑配置有什么要求?不能运行H128只能运行H64的电脑能运行SAE吗
可以,但是不能用SAE的默认配置,需要修改参数。
可以参考这篇文章:https://www.deepfakescn.com/?p=255
有详细的参数配置样例
请问,我的是打开了模型 ,跑到前面几十个数字,之后就不动了,是什么导致的?
黑色窗口底部跳动的数字出现了吗? 预览窗口跳出来了? 如果答案是否,那么你并没有成功启动模型。如果是,那么在黑色命令行窗口回车一下,数字重新开始跳动,就继续训练了。
一直没动也没出县什么loss
AMD的CPU在运行以上文件时并没有在工作,反而是CPU在一直跑,这是怎么回事?显卡是AMD Radeon VII
呸,是AMD的GPU没工作
OpenCL版是支持AMD显卡的,但是不确定是否支持所有显卡! N卡方面几乎是100%支持的。
你好,请问:在网上下载的已训练好的模型,如何使用? 没有原来的src 脸图,也能训练吗?
cannot convert float NaN to integer
你好 在进行train的时候报了这个错 会有影响吗?好像程序还在运行
这个提示是不太正常哎
你好
想问一下
可以在加载模型时修改参数吗
训练模型刚开始的时候,在黑色串口上快速回车,即可进入配置模式,部分参数可以修改。有些参数只能在第一次跑模型的时候设置。
好的
还有一个问题:
训练时发现有些不符合的图片 模型
可以在不训练的时候删除掉吗
删了后训练会不会报错之类的
可以,不会报错!
你好,请问训练可以暂停,然后继续开始么,怎么操作?
可以! 直接关闭黑色命令行窗口,或者在头像预览窗口按回车键(Enter)。推荐后者!
你好,我在训练的一直遇到一个问题。开始的时候源和目标loss都在降低,大概到1左右后都会突然增加到3,就是最上面。我换了不同的视频都这样,我想问一下它本身学习loss是一个单调递减的状态还是重复由高到低的过程?
正常是:震荡降低,整个趋势变高肯定是不对的!
我用两台电脑做测试,一台低配一点是震荡降低,另一台是降低到某个点会突然升高,我截了图:https://img删掉chr.com/i/EOxU6U 。看那个曲线会突然到峰值 预览图会缺失一块。这个可能是什么原因呢
你那个图是跑蹦了,就是跑坏了。原因目前不好说!
站长,我想问一下训练出来的模型data SRC.h5是只针对当前dst训练的吗?我保留src替换dst成别的视频再训练能继承之前src的模型吗
可以!
站长你好,我又来问问题了~请问h64和h128训练模型最后的精度是不同的吗?比如h64训练最后得到的脸部图片只有preview里那种分辨率是清晰的,反之128可以训练更高清晰度的脸?
对,这两个模型就是分辨率的差别!
站长,在用h64训练30多个小时后,突然停止了,关闭之后再打开6) train H64.bat后出现下面的这些,请问怎么解决啊?
Running trainer.
Loading model…
Press enter in 2 seconds to override model settings.Using TensorFlow backend.
Loading: 100%|####################################################################| 2269/2269 [00:02<00:00, 781.16it/s]
Loading: 100%|#################################################################################################| 1557/1557 [00:01<00:00, 897.72it/s]
===== Model summary =====
== Model name: H64
==
== Current iteration: 263590
==
== Model options:
== |== batch_size : 4
== |== sort_by_yaw : False
== |== random_flip : True
== |== lighter_ae : False
== |== pixel_loss : False
== Running on:
== |== [0 : GeForce GTX 1060 6GB]
=========================
Starting. Press "Enter" to stop training and save model.
2019-07-03 18:50:33.830317: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.832677: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.834839: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.836750: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.856440: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.858632: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.860588: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.862620: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.865322: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.867617: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.869627: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:33.871608: E tensorflow/stream_executor/cuda/cuda_blas.cc:464] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2019-07-03 18:50:34.721624: E tensorflow/stream_executor/cuda/cuda_dnn.cc:373] Could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED
2019-07-03 18:50:34.724325: E tensorflow/stream_executor/cuda/cuda_dnn.cc:373] Could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED
2019-07-03 18:50:34.726286: E tensorflow/stream_executor/cuda/cuda_dnn.cc:373] Could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED
2019-07-03 18:50:34.729176: E tensorflow/stream_executor/cuda/cuda_dnn.cc:373] Could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED
Error: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[{{node model_1/conv2d_1/convolution}} = Conv2D[T=DT_FLOAT, _class=["loc:@train…propFilter"], data_format="NCHW", dilations=[1, 1, 1, 1], padding="SAME", strides=[1, 1, 2, 2], use_cudnn_on_gpu=true, _device="/job:localhost/replica:0/task:0/device:GPU:0"](training/Adam/gradients/model_1/conv2d_1/convolution_grad/Conv2DBackpropFilter-0-TransposeNHWCToNCHW-LayoutOptimizer, conv2d_1/kernel/read)]]
[[{{node loss/model_3_loss_1/Mean_3/_663}} = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name="edge_4739_loss/model_3_loss_1/Mean_3", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]]
Traceback (most recent call last):
File "F:\DeepFaceLab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\mainscripts\Trainer.py", line 78, in trainerThread
loss_string = model.train_one_iter()
File "F:\DeepFaceLab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\models\ModelBase.py", line 358, in train_one_iter
losses = self.onTrainOneIter(sample, self.generator_list)
File "F:\DeepFaceLab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\models\Model_H64\Model.py", line 85, in onTrainOneIter
total, loss_src_bgr, loss_src_mask, loss_dst_bgr, loss_dst_mask = self.ae.train_on_batch( [warped_src, target_src_full_mask, warped_dst, target_dst_full_mask], [target_src, target_src_full_mask, target_dst, target_dst_full_mask] )
File "F:\DeepFaceLab\DeepFaceLabCUDA10.1AVX\_internal\python-3.6.8\lib\site-packages\keras\engine\training.py", line 1217, in train_on_batch
outputs = self.train_function(ins)
File "F:\DeepFaceLab\DeepFaceLabCUDA10.1AVX\_internal\python-3.6.8\lib\site-packages\keras\backend\tensorflow_backend.py", line 2715, in __call__
return self._call(inputs)
File "F:\DeepFaceLab\DeepFaceLabCUDA10.1AVX\_internal\python-3.6.8\lib\site-packages\keras\backend\tensorflow_backend.py", line 2675, in _call
fetched = self._callable_fn(*array_vals)
File "F:\DeepFaceLab\DeepFaceLabCUDA10.1AVX\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py", line 1439, in __call__
run_metadata_ptr)
File "F:\DeepFaceLab\DeepFaceLabCUDA10.1AVX\_internal\python-3.6.8\lib\site-packages\tensorflow\python\framework\errors_impl.py", line 528, in __exit__
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[{{node model_1/conv2d_1/convolution}} = Conv2D[T=DT_FLOAT, _class=["loc:@train…propFilter"], data_format="NCHW", dilations=[1, 1, 1, 1], padding="SAME", strides=[1, 1, 2, 2], use_cudnn_on_gpu=true, _device="/job:localhost/replica:0/task:0/device:GPU:0"](training/Adam/gradients/model_1/conv2d_1/convolution_grad/Conv2DBackpropFilter-0-TransposeNHWCToNCHW-LayoutOptimizer, conv2d_1/kernel/read)]]
[[{{node loss/model_3_loss_1/Mean_3/_663}} = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name="edge_4739_loss/model_3_loss_1/Mean_3", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]]
Done.
请按任意键继续. . .
已解决,是没安装CUDNN
deepfake也需要安装么?只装了cuda不够?
请问没安装CUDNN什么意思,怎么安装?
已解决
好,可以给其他人参考下!
站長你好, 小弟新手一枚想問個問題
假設我原本scr的原圖只有700, 面圖650(砍掉沒抓到臉的)
後來又花了點時間蒐集同個人的素材, scr的原圖增加到1500張
此時的做法, 是跟之前一樣直接跑提取面圖的bat嗎?(需不需要刪除第一次跑的原圖or面圖?)
站長你好, 小弟新手一枚想問個問題
假設我原本scr的原圖只有700, 面圖650(砍掉沒抓到臉的)
後來又花了點時間蒐集同個人的素材, scr的原圖增加到1500張
此時的做法, 是跟之前一樣直接跑提取面圖的bat嗎?(需不需要刪除第一次跑的原圖or面圖?)
提取的时候会询问你是否覆盖!
站长你好,我在训练这一步出现了错误,是啥问题呢
Running trainer.
Loading model…
Model first run. Enter model options as default for each run.
Enable autobackup? (y/n ?:help skip:n) :
n
Write preview history? (y/n ?:help skip:n) :
n
Target iteration (skip:unlimited/default) :
0
Batch_size (?:help skip:0) :
0
Feed faces to network sorted by yaw? (y/n ?:help skip:n) :
n
Flip faces randomly? (y/n ?:help skip:y) :
y
Src face scale modifier % ( -30…30, ?:help skip:0) :
0
Use lightweight autoencoder? (y/n, ?:help skip:n) :
n
Use pixel loss? (y/n, ?:help skip: n/default ) :
n
Using TensorFlow backend.
Loading: 100%|###############################| 301/301 [00:06<00:00, 48.09it/s]
Loading: 100%|##############################| 426/426 [00:02<00:00, 160.87it/s]
===== Model summary =====
== Model name: H64
==
== Current iteration: 0
==
== Model options:
== |== batch_size : 4
== |== sort_by_yaw : False
== |== random_flip : True
== |== lighter_ae : False
== |== pixel_loss : False
== Running on:
== |== [0 : GeForce 920M]
==
== WARNING: You are using 2GB GPU. Result quality may be significantly decreased
.
== If training does not start, close all programs and try again.
== Also you can disable Windows Aero Desktop to get extra free VRAM.
==
=========================
Starting. Press "Enter" to stop training and save model.
Error: OOM when allocating tensor with shape[5,5,512,1024] and type float on /jo
b:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
……
Done.
请按任意键继续. . .
oom,显存太小了!是2G么? Use lightweight autoencoder? 输入y,启用轻量级!
请问下查看显存配置是16G,为啥运行这一步的时候也是提示显存2G呀~
训练大概10张之后就报error了,除非选择轻量化~
你用的是比较老的版本吧,可以用新一点的没有这个问题。
想问一下,模型训练了很长时间,想暂停一下,之后再继续。是直接关闭黑色命令行窗口,或者在头像预览窗口按回车键? 之后再重开训练,能回复至先前的进度吗?
都可以,能自动保存进度!
===== Model summary =====
== Model name: H128
==
== Current iteration: 0
==
== Model options:
== |== batch_size : 32
== |== sort_by_yaw : False
== |== random_flip : True
== |== lighter_ae : False
== |== pixel_loss : False
== Running on:
== |== [0 : GeForce RTX 2060]
=========================
Starting. Press "Enter" to stop training and save model.
Error: OOM when allocating tensor with shape[32,512,64,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
…..
Done.
請按任意鍵繼續 . . .
這是出甚麼問題? 不讓我訓練 訓練的窗口也沒有出來 就寫這串字 請幫助我一下 謝謝
OOM 你显存不够,把batch_size 改小一些!如果你显存是小于6G 你可能还需要启用轻量级。
2060 6G 這顯存應該夠了吧 為甚麼就是不給跑呢?….只能用輕量級的跑 是不是哪邊出問題了
6G 你bs也不能开太大啊。太大了自然崩了!
大佬为什么我的机子在训练时CPU是百分百而gpu只占用零呢?该如何调用gpu训练呀
只要是AVX版,SSE版能跑的话肯定是调用GPU的,openCL可能会调用CPU
谢谢站长,但是我用AVX版本的话执行第四步显示的是
Performing 1st pass…
Running on Generic GeForce GPU #0.
100%|################################################################################| 138/138 [00:17<00:00, 8.06it/s]
Performing 2nd pass…
Running on Generic GeForce GPU.
这是为什么呢
好了。。速度太慢没显示过来 谢谢!
站长您好,我的显卡是2070 但是命令行没有显示显卡型号, 8g显存显示的却是2GB GPU,而且看了下gpu占用一直没有超过百分之十,麻烦请教一下您这几个问题怎么解决呢
== Model name: H128
==
== Current iteration: 0
==
== Model options:
== |== batch_size : 4
== |== sort_by_yaw : False
== |== random_flip : True
== |== lighter_ae : False
== |== pixel_loss : False
== Running on:
== |== [0 : Generic GeForce GPU]
==
== WARNING: You are using 2GB GPU. Result quality may be significantly decreased.
== If training does not start, close all programs and try again.
== Also you can disable Windows Aero Desktop to get extra free VRAM.
应该是驱动问题,没有识别出具体的型号。更新一下驱动试试!
你好,这个问题解决了吗,我也遇到一样的问题。
保存退出之后再进行训练的时候,总是不确定时间出现按任意键继续,然后就得重新启动,这是什饿情况啊,一会就得看一下
batchsize 调小试试!
batchsize一直用的8,第一次的时候没什么问题,一直在训练,但是保存退出之后再次训练有时候才几分钟就出现按任意键继续,有时候却能很长时间保持训练,是因为电脑不断地在换GPU或者CPU导致不稳定的吗,就是、觉得需要总去看一看比较麻烦。
== Model name: H128
==
== Current iteration: 932302
==
== Model options:
== |== autobackup : True
== |== write_preview_history : True
== |== batch_size : 16
== |== sort_by_yaw : False
== |== random_flip : True
== |== lighter_ae : True
== |== pixel_loss : False
== Running on:
== |== [0 : GeForce GTX 1660 Ti]
=========================
Starting. Press “Enter” to stop training and save model.
Error: integer division or modulo by zero
Traceback (most recent call last):
File “E:\Users\USER\Downloads\DFA\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\mainscripts\Trainer.py”, line 107, in trainerThread
iter, iter_time = model.train_one_iter()
File “E:\Users\USER\Downloads\DFA\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\models\ModelBase.py”, line 470, in train_one_iter
sample = self.generate_next_sample()
File “E:\Users\USER\Downloads\DFA\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\models\ModelBase.py”, line 467, in generate_next_sample
return [next(generator) for generator in self.generator_list]
File “E:\Users\USER\Downloads\DFA\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\models\ModelBase.py”, line 467, in
return [next(generator) for generator in self.generator_list]
File “E:\Users\USER\Downloads\DFA\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\samplelib\SampleGeneratorFace.py”, line 58, in __next__
generator = self.generators[self.generator_counter % len(self.generators) ]
ZeroDivisionError: integer division or modulo by zero
Done.
請按任意鍵繼續 . . .
这个一般和图片有关系,是不是动过workplace里的什么东西了。
站長您好,請問第四列全白色,其餘都正常是不是什麼地方沒設好?我發現這會導致臉部光影與dst不符合,謝謝
站长你好,在训练的时候我的CPU占用率在70%左右,但GPU占用率却只有10%-20%,GPU是NVIDIA GeForce GTX 1060,请问这是正常现象吗?怎样设置能让GPU占用率提升?
正常的,显存用上了,占有率不一定高!
站长您好,最近遇到的奇怪问题。
之前一直用OpenFaceSwap,一直很顺利,有一天忽然在Train的环节开始报错:
OSError: Can’t write data (file write failed:
特别的,total write size = 52428800, bytes this sub-write = 52428800, bytes actually written = 18446744073709551615, offset = 16447032
这个肯定不是磁盘空间的问题了,大概率是segmentation的问题,然而各种重装依然无法解决。
于是决定直接使用DeepFaceLab,没想到到train的环节依然报错。
而且报的是一样的错。
站长您遇到过吗?可能是什么原因?有没有什么解决方法?
这个没遇到,不过他说的比较清楚 OSError ,系统错误 不能读取数据。 如果换软件都不行,肯定在系统层面,而非软件本身问题。
为什么合成的图,脸部边缘没有羽化模型过渡效果? 二十很生硬的一个替换上去的方块状脸部? 需要设置什么参数吗?
站长你好!请问模型训练过程中如果暂停了训练,关了电脑。下次想继续训练之前暂停的模型,也是跟初次训练一样打开train命令吗?我试了一次,重新打开train命令又要输入各种参数,也不知道是否继续了上次的训练进度。
对的! 打开同一个文件,他默认是15分钟保存一次,如果你第一次没到时间,那么第二次肯定是重新配置参数。如果时间过了,第二次就能继续。 手动保存可以在预览窗口 按 S
站长你好,我这 4] data_src extract faces DLIB all GPU debug.bat 就出了问题,搞不懂哪里安装失败。
Performing 1st pass…
Running on GeForce 830M #0.
Exception: Traceback (most recent call last):
File “C:\Users\CRAB5\OneDrive\桌面\deepfacelab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\joblib\SubprocessorBase.py”, line 58, in _subprocess_run
self.on_initialize(client_dict)
File “C:\Users\CRAB5\OneDrive\桌面\deepfacelab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\mainscripts\Extractor.py”, line 58, in on_initialize
self.e.__enter__()
File “C:\Users\CRAB5\OneDrive\桌面\deepfacelab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\facelib\DLIBExtractor.py”, line 16, in __enter__
self.dlib_cnn_face_detector = self.dlib.cnn_face_detection_model_v1( str(Path(__file__).parent / “mmod_human_face_detector.dat”) )
RuntimeError: Unable to open C:\Users\CRAB5\OneDrive\桌面\deepfacelab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\facelib\mmod_human_face_detector.dat for reading.
Traceback (most recent call last):
File “C:\Users\CRAB5\OneDrive\桌面\deepfacelab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\main.py”, line 195, in
arguments.func(arguments)
File “C:\Users\CRAB5\OneDrive\桌面\deepfacelab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\main.py”, line 33, in process_extract
‘multi_gpu’ : arguments.multi_gpu,
File “C:\Users\CRAB5\OneDrive\桌面\deepfacelab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\mainscripts\Extractor.py”, line 586, in main
extracted_rects = ExtractSubprocessor ([ (x,) for x in input_path_image_paths ], ‘rects’, image_size, face_type, debug, multi_gpu=multi_gpu, cpu_only=cpu_only, manual=False, detector=detector).run()
File “C:\Users\CRAB5\OneDrive\桌面\deepfacelab\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\joblib\SubprocessorBase.py”, line 179, in run
raise Exception ( “Unable to start subprocesses.” )
Exception: Unable to start subprocesses.
Press any key to continue . . .
站长你好!请问模型训练由左而右的第四张图 变成绿色 而训练进度也從0.1xxx变2.3xxx
這樣還有救嗎?
第四张图由上而下整排
15分钟内关了,启动还有机会,否则就没办法了!
训练两天,系统盘被塞了快10个G了(我软件放D盘),是缓存文件吗,具体位置在哪,合成后能删除吗?
额,这个软件没有缓存呀。所有的文件都在workspace !软件在D盘那么文件肯定也在D盘,系统盘增加考虑其他因素。
Running trainer.
Loading model…
Model first run. Enter model options as default for each run.
Write preview history? (y/n ?:help skip:n) :
n
Target iteration (skip:unlimited/default) :
0
Batch_size (?:help skip:0/default) : 4
Feed faces to network sorted by yaw? (y/n ?:help skip:n) :
n
Flip faces randomly? (y/n ?:help skip:y) :
y
Src face scale modifier % ( -30…30, ?:help skip:0) :
0
Use lightweight autoencoder? (y/n, ?:help skip:n) :
n
Use pixel loss? (y/n, ?:help skip: n/default ) :
n
Using TensorFlow backend.
Loading: 100%|#######################################################################| 654/654 [00:08<00:00, 77.61it/s]
Loading: 0it [00:00, ?it/s]
Error: integer division or modulo by zero
Traceback (most recent call last):
File "D:\DF\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\mainscripts\Trainer.py", line 41, in trainerThread
device_args=device_args)
File "D:\DF\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\models\ModelBase.py", line 163, in __init__
self.sample_for_preview = self.generate_next_sample()
File "D:\DF\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\models\ModelBase.py", line 353, in generate_next_sample
return [next(generator) for generator in self.generator_list]
File "D:\DF\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\models\ModelBase.py", line 353, in
return [next(generator) for generator in self.generator_list]
File “D:\DF\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\samples\SampleGeneratorFace.py”, line 57, in __next__
generator = self.generators[self.generator_counter % len(self.generators) ]
ZeroDivisionError: integer division or modulo by zero
Done.
请按任意键继续. . .
大佬,这个这么搞
缺少步骤,只提取了src,没有提取dst
站長您好,想請問一下要注意什麼比較能避免模型崩潰?
我跑了兩次訓練,都跑好幾天,但最後都會崩潰
(第一次試SAE在約0.8左右崩潰、第二次試H128在約0.6左右崩潰)
不知是否與src或dst的臉數有關?
(我src參考網上建議為1500張,dst擷取原14分鐘視頻約25000張)
或是dst要刪除側臉(感覺側臉很難訓練出來)或臉部不完整(有時會extract出只有半臉的圖)的圖片?
煩請指教,謝謝您
崩溃是偶发的,没法断定,但是肯定和素材有关。SAE老版本是很容易蹦,但是新版本好多了。H128很少会蹦的。
站长您好,我跑h128模型已经崩溃两侧了,错误代码是:
Traceback (most recent call last):
File “multiprocessing\process.py”, line 258, in _bootstrap
File “multiprocessing\process.py”, line 93, in run
File “D:\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\utils\iter_utils.py”, line 39, in process_func
gen_data = next (self.generator_func)
File “D:\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\samples\SampleGeneratorFace.py”, line 166, in batch_func
yield [ np.array(batch) for batch in batches]
File “D:\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\samples\SampleGeneratorFace.py”, line 166, in
yield [ np.array(batch) for batch in batches]
MemoryError
然后windows就提示python错误了
我第一次batch size设置成32
第二次设置成16
是在谷歌云跑的
请问是怎么回事呢
站长您好,能帮我看看是哪里出现问题吗?
我准备训练就出现如下错误
我该怎么做?
==————– Running On —————==
== ==
== Device index: 0 ==
== Name: GeForce GTX 1660 ==
== VRAM: 6.00GB ==
== ==
=============================================
Starting. Press “Enter” to stop training and save model.
2019-08-20 15:50:43.428361: E tensorflow/stream_executor/cuda/cuda_driver.cc:806] failed to allocate 557.91M (585013504 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
Done.
请按任意键继续. . .
内存溢出了。尝试调低BS 或者 升级显存!
站长啊~
有些镜头想要换脸的目标在接吻,切出来的头像是两个人接吻的,开始训练之前这种头像需要删除吗?
如果想替换接吻的两个人中的一个人,怎么设置呢?
作为dst的话肯定不能删,删了就不换了。 即便两个人同框,提取的时候也会有重点的。这个debug里可以看出来。有的图是女的为主,有的图是男的为主。如果是两个男的接吻,那当我没说~~^_^! 还有,接吻视频还是比较难换的。
是可以删掉一些dst 里面align的图片的,但要备份好,train完之后再拷贝回来,然后再 convert。这样最后转的时候就不会少图片。但是不管怎样这些有交互的两人角度都比较难处理。
我也遇到这个问题,我的情况是我的dst视频有很多时候脸被切掉一半,这些部分我不太清楚包含在train里是加分还是减分,我就把他们先backup,删掉了最后convert的时候再拿回来。
您好~我器材室笔记本
CPU: i7-8750H 12核
显卡: GTX 1070 8G
内存: 16G
用H128训练 Batch_size 手动选择16
GPU利用率55%左右
专用GPU内存利用率7G左右
CPU利用率30%左右
内存利用率 7.5G左右
请问这样合理吗,或者您推荐个模式和参数能让我的机器充分发挥出来性能,十分感谢!
补充一下
软件用的 CUDA9.2SSE 03-013-2019的,放到固态硬盘上使用
CUDA安装的10.1(因为之前用的软件是10.1AVX的,看了网站教程又改的现在的,这个也请指点!)
DST文件350M,时长不到5分钟,分离出的PNG图片不到7K张
SRC文件240M,市场3分10秒,分理出的PNG5.7K
这个利用率是软件自动分配的。 1070 基本都是GPU占用50%左右。
Running trainer.
Loading model…
Using TensorFlow backend.
Loading: 100%|####################################################################| 8494/8494 [00:11<00:00, 728.15it/s]
Loading: 100%|####################################################################| 3012/3012 [00:03<00:00, 954.16it/s]
===== Model summary =====
== Model name: H128
==
== Current iteration: 0
==
== Model options:
== |== write_preview_history : True
== |== batch_size : 4
== |== sort_by_yaw : False
== |== random_flip : True
== |== lighter_ae : False
== |== pixel_loss : False
== Running on:
== |== [0 : GeForce GTX 1060 3GB]
=========================
Saving….
Starting. Press "Enter" to stop training and save model.
Error: OOM when allocating tensor with shape[65536,512] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
能帮帮忙吗?
OOM了,3GB显存跑不了H128,只能跑启用了轻量级的H64
站长您好,能帮我看看是哪里出现问题吗?
我准备训练就出现如下错误
Starting. Press “Enter” to stop training and save model.
Error: OOM when allocating tensor with shape[8,126,128,128] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
solve thanks
OOM out of memory 内存溢出了。 把bs改小,或者尝试启用轻量级。
在执行训练的H64的时候出现的,请大家帮忙看一下是什么问题。
Running trainer.
Loading model…
Model first run. Enter model options as default for each run.
Write preview history? (y/n ?:help skip:n) :
n
Target iteration (skip:unlimited/default) :
0
Batch_size (?:help skip:0/default) :
0
Feed faces to network sorted by yaw? (y/n ?:help skip:n) :
n
Flip faces randomly? (y/n ?:help skip:y) :
y
Src face scale modifier % ( -30…30, ?:help skip:0) :
0
Use lightweight autoencoder? (y/n, ?:help skip:n) :
n
Use pixel loss? (y/n, ?:help skip: n/default ) :
n
Using TensorFlow backend.
Loading: 100%|##################################################################| 11873/11873 [00:16<00:00, 718.23it/s]
Loading: 0it [00:00, ?it/s]
Error: integer division or modulo by zero
Traceback (most recent call last):
File "E:\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\mainscripts\Trainer.py", line 41, in trainerThread
device_args=device_args)
File "E:\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\models\ModelBase.py", line 163, in __init__
self.sample_for_preview = self.generate_next_sample()
File "E:\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\models\ModelBase.py", line 353, in generate_next_sample
return [next(generator) for generator in self.generator_list]
File "E:\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\models\ModelBase.py", line 353, in
return [next(generator) for generator in self.generator_list]
File “E:\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\samples\SampleGeneratorFace.py”, line 57, in __next__
generator = self.generators[self.generator_counter % len(self.generators) ]
ZeroDivisionError: integer division or modulo by zero
Done.
请按任意键继续. . .
已解决,请忽视,谢谢
请问如何解决,感谢!
dst下面没有头像。
你好站长,我训练的时候能跑是能跑,但是有个报错,说我什么内存无法分配。SAE模型
Starting. Press “Enter” to stop training and save model.
2019-09-13 11:07:41.626264: E tensorflow/stream_executor/cuda/cuda_driver.cc:806] failed to allocate 2.18G (2344463104 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory
[11:07:46][#000001][9346ms][1.6852][1.2746]
[11:22:49][#001041][0835ms][1.3958][0.7930]
20xx 系列显卡么? 新版会有这个提示,可以忽略。
站長你好,,在訓練模型的時候會發現有些頭像是顛倒的,這會造成甚麼影響嗎?
在排序的時候都是正的
这种图片还是删掉比较好。
站长你好,请问一下为什么我每次训练的时候都弹出
Starting. Press “Enter” to stop training and save model.
就不动了,重启过很多次了也没有反应
这个要等等呀!第一次可能比较慢的。
站長好
謝謝幫忙
如果第四列變成白色我不小心讓他save了一次,我整個model是壞掉要重跑還是有機會救回來?
如果不行我這個model就是不能用在future training了?
謝謝~
站长好~我是运行了三个多小时后报错了,不知道什么原因,重新运行后一段时间,依旧报这个错误
Starting. Press “Enter” to stop training and save model.
2019-09-20 15:49:30.380575: E tensorflow/stream_executor/cuda/cuda_driver.cc:1011] could not synchronize on CUDA context: CUDA_ERROR_LAUNCH_FAILED: unspecified launch failure ::
Error: GPU sync failed
Traceback (most recent call last):
File “E:\deepfacelab\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\mainscripts\Trainer.py”, line 107, in trainerThread
iter, iter_time = model.train_one_iter()
File “E:\deepfacelab\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\models\ModelBase.py”, line 472, in train_one_iter
losses = self.onTrainOneIter(sample, self.generator_list)
File “E:\deepfacelab\DeepFaceLabCUDA9.2SSE\_internal\DeepFaceLab\models\Model_H64\Model.py”, line 89, in onTrainOneIter
total, loss_src_bgr, loss_src_mask, loss_dst_bgr, loss_dst_mask = self.ae.train_on_batch( [warped_src, target_src_full_mask, warped_dst, target_dst_full_mask], [target_src, target_src_full_mask, target_dst, target_dst_full_mask] )
File “E:\deepfacelab\DeepFaceLabCUDA9.2SSE\_internal\python-3.6.8\lib\site-packages\keras\engine\training.py”, line 1217, in train_on_batch
outputs = self.train_function(ins)
File “E:\deepfacelab\DeepFaceLabCUDA9.2SSE\_internal\python-3.6.8\lib\site-packages\keras\backend\tensorflow_backend.py”, line 2715, in __call__
return self._call(inputs)
File “E:\deepfacelab\DeepFaceLabCUDA9.2SSE\_internal\python-3.6.8\lib\site-packages\keras\backend\tensorflow_backend.py”, line 2675, in _call
fetched = self._callable_fn(*array_vals)
File “E:\deepfacelab\DeepFaceLabCUDA9.2SSE\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py”, line 1439, in __call__
run_metadata_ptr)
File “E:\deepfacelab\DeepFaceLabCUDA9.2SSE\_internal\python-3.6.8\lib\site-packages\tensorflow\python\framework\errors_impl.py”, line 528, in __exit__
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.InternalError: GPU sync failed
Done.
请按任意键继续. . .
没见过这个错误~~
loss值到了一定程度就很难下去,然而预览的效果也得不到预期,看上去细节清晰度不够,是不是可以通过调大AutoEncoder dims、Encoder dims per channel和Decoder dims per channel这几个值来解决呢?现在用的是它默认值
站长 你好,我没有添加SRC视频,未进行 2) extract images from video data_src (SRC视频转图片);直接把网上保存的图片放到workspace/data_src下,然后进行面部图片提取,后面几步进行的都没有问题,但最后却未合成MP4文件,请问是怎么回事?不是说可以用图片的吗?
网上图片不行的。需要重新提取下!
站长麻烦请问下 如果我一个短视频和一个长视频合。一个图少 一个图多 会是和2个一样时间的视频 合出来时间一样吗。 还是视频越短合的越快 可不可以面部少合 会不会快点。
一张图和十张图,训练模型的时间并没有太大差别。
站长你好, 请问如果训练了中途后换了块显卡, 训练还能继续吗还是要从新训练
可以的。只要新卡驱动装好。继续跑就可以了。
站长你好. 请问我训练到iteration 数到快190万了, 这个数字越大感觉preview好像越慢, 有没有办法把这个数字重置但还是保持训练记录呢? 谢谢
preview不影响什么的。Iter是迭代数,仅仅是一个数字而已!所以可以不用动。
好的谢谢!
为什么我的Batch_size调到2都还会报OOM错误,我的显卡是GTX1050ti,4g显存,是和图片太多有关吗?我的src
aligned图片是4000多张,dst aligned图片是11000多张。
Fury X 的 4G HBM 显存就算bs拉到32也不会爆,是自带不爆加成吗?想升级显卡,用HBM2的显卡会好点吗?
bs从4递增到32显存占用一直都是3.6G左右
站长你好!每次训练几分钟就会跳这个能说一下是什么问题吗?
Process Process-2:4][0284ms][0.5435][1.2659]
Traceback (most recent call last):
File “K:\DeepFaceLab_CUDA_10.1_AVX\_internal\DeepFaceLab\samplelib\SampleGeneratorFace.py”, line 140, in batch_func
x = SampleProcessor.process (sample, self.sample_process_options, self.output_sample_types, self.debug, ct_sample=ct_sample)
File “K:\DeepFaceLab_CUDA_10.1_AVX\_internal\DeepFaceLab\samplelib\SampleProcessor.py”, line 229, in process
img = do_transform (img, mask)
File “K:\DeepFaceLab_CUDA_10.1_AVX\_internal\DeepFaceLab\samplelib\SampleProcessor.py”, line 181, in do_transform
img = np.concatenate( (img, mask ), -1 )
File “”, line 6, in concatenate
numpy.core._exceptions.MemoryError: Unable to allocate array with shape (256, 256, 4) and data type float32
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “multiprocessing\process.py”, line 258, in _bootstrap
File “multiprocessing\process.py”, line 93, in run
File “K:\DeepFaceLab_CUDA_10.1_AVX\_internal\DeepFaceLab\utils\iter_utils.py”, line 39, in process_func
gen_data = next (self.generator_func)
File “K:\DeepFaceLab_CUDA_10.1_AVX\_internal\DeepFaceLab\samplelib\SampleGeneratorFace.py”, line 142, in batch_func
raise Exception (“Exception occured in sample %s. Error: %s” % (sample.filename, traceback.format_exc() ) )
Exception: Exception occured in sample K:\DeepFaceLab_CUDA_10.1_AVX\workspace\data_src\aligned\mmexport1568535000130_0.jpg. Error: Traceback (most recent call last):
File “K:\DeepFaceLab_CUDA_10.1_AVX\_internal\DeepFaceLab\samplelib\SampleGeneratorFace.py”, line 140, in batch_func
x = SampleProcessor.process (sample, self.sample_process_options, self.output_sample_types, self.debug, ct_sample=ct_sample)
File “K:\DeepFaceLab_CUDA_10.1_AVX\_internal\DeepFaceLab\samplelib\SampleProcessor.py”, line 229, in process
img = do_transform (img, mask)
File “K:\DeepFaceLab_CUDA_10.1_AVX\_internal\DeepFaceLab\samplelib\SampleProcessor.py”, line 181, in do_transform
img = np.concatenate( (img, mask ), -1 )
File “”, line 6, in concatenate
numpy.core._exceptions.MemoryError: Unable to allocate array with shape (256, 256, 4) and data type float32
看之后一行提示是内存(显存)错误。是不是内存不够?
噢,多谢站长,是内存炸了,因为机子是16G内存所以没想过这点。刚刚发现可使用内存才7G多,重新拔插内存条恢复了。还有个问题,我在训练H64的时候设置里没有找到关于轻量级的选项,但是训练时默认lighter_ae: True。是不是新版软件H64默认是轻量级不能改了?
Running trainer.
Loading model…
Model first run. Enter model options as default for each run.
Write preview history? (y/n ?:help skip:n) : y
Target iteration (skip:unlimited/default) :
0
Batch_size (?:help skip:0/default) : 4
Feed faces to network sorted by yaw? (y/n ?:help skip:n) :
n
Flip faces randomly? (y/n ?:help skip:y) :
y
Src face scale modifier % ( -30…30, ?:help skip:0) :
0
Use lightweight autoencoder? (y/n, ?:help skip:n) : n
Use pixel loss? (y/n, ?:help skip: n/default ) : n
Using TensorFlow backend.
Loading: 100%|######################################################################| 654/654 [00:00<00:00, 819.58it/s]
Loading: 100%|####################################################################| 1506/1506 [00:01<00:00, 965.41it/s]
===== Model summary =====
== Model name: H64
==
== Current iteration: 0
==
== Model options:
== |== write_preview_history : True
== |== batch_size : 4
== |== sort_by_yaw : False
== |== random_flip : True
== |== lighter_ae : False
== |== pixel_loss : False
== Running on:
== |== [0 : GeForce RTX 2080 Ti]
=========================
Saving….
Starting. Press "Enter" to stop training and save model.
请按任意键继续. . .
按任意键继续没反应,请问是什么问题?
Saving….
Starting. Press “Enter” to stop training and save model.
2019-11-28 10:43:32.215131: E tensorflow/stream_executor/cuda/cuda_dnn.cc:373] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
2019-11-28 10:43:32.225994: E tensorflow/stream_executor/cuda/cuda_dnn.cc:373] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
2019-11-28 10:43:32.232389: E tensorflow/stream_executor/cuda/cuda_dnn.cc:373] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
fatal : Memory allocation failure
2019-11-28 10:43:32.238420: E tensorflow/stream_executor/cuda/cuda_dnn.cc:373] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
Error: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
请按任意键继续. . .
不知道是什么问题,各种报错,cudnn之前有手动装过了,也不知道有没有装好,这个报错内容不是固定的也不能说随机的吧,或许都有问题吧
重新打开有时还会报这个错BrokenPipeError: [Errno 32] Broken pipe
求问一下,h128 如果要train到跟h64 一个等级的细节(当然h128潜力更大),是不是要h64 四倍的时间?
站长有个问题想请教,想知道data多少和训练时长直接的关系,到同等清晰度,10张,100张,1000张,10000张和10w张图,时间上是个什么关系?
要到同样清晰度,越多越长!
问个问题 是不是可以这样呢?
A和B 训练 迭失到 100W model
之后用来 训练 C和D 迭失从100W 训练到200W
之后这个model 继续用来训练 E和F 从200W 训练到300W
这样累计到 1000W 是不是会弄到一个很好的model ?
谢谢
你好,想請問我用train SAE 時候會出現
============================= Model Summary =============================
== ==
== Model name: SAE ==
== ==
== Current iteration: 5096 ==
== ==
==————————— Model Options —————————==
== ==
== autobackup: True ==
== random_flip: True ==
== resolution: 128 ==
== face_type: f ==
== learn_mask: True ==
== optimizer_mode: 1 ==
== archi: df ==
== ae_dims: 512 ==
== e_ch_dims: 42 ==
== d_ch_dims: 21 ==
== ca_weights: False ==
== pixel_loss: False ==
== face_style_power: 0.0 ==
== bg_style_power: 0.0 ==
== ct_mode: none ==
== clipgrad: False ==
== batch_size: 4 ==
== ==
==—————————- Running On —————————–==
== ==
== Device index: 0 ==
== Name: NVIDIA Corporation GeForce GTX 1060 6GB (OpenCL) ==
== VRAM: 6.00GB ==
== ==
=========================================================================
Starting. Press “Enter” to stop training and save model.
INFO:plaidml:Analyzing Ops: 231 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 399 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 420 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 444 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 465 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 489 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 509 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 530 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 824 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 945 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 966 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 990 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 1011 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 1035 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 1055 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 1076 of 2449 operations complete
INFO:plaidml:Analyzing Ops: 2139 of 2449 operations complete
ERROR:plaidml:unable to run OpenCL kernel: CL_MEM_OBJECT_ALLOCATION_FAILURE
INFO:plaidml:Analyzing Ops: 324 of 918 operations complete
INFO:plaidml:Analyzing Ops: 337 of 918 operations complete
INFO:plaidml:Analyzing Ops: 496 of 918 operations complete
INFO:plaidml:Analyzing Ops: 881 of 918 operations complete
[01:33:44][#006277][0134ms][0.0000][0.0000]
之間就時間照計但其他數字就沒有跳,請問是什麼問題??
謝謝幫忙
N卡请用cuda版本!
站长好。问一下,我在训练的时候没有弹出预览窗口是什么原因,而且训练一直继续,已经24小时了
站长好!请问使用H64模型报错:ValueError: gen_warp_params accepts only square images. 是为什么?都是使用自带的素材。
这个提示一般是素材问题引起的。aligned素材要求正方形图片。
这个是咋回事啊?
ERROR:plaidml:unable to run OpenCL kernel: CL_MEM_OBJECT_ALLOCATION_FAILURE
下面一直在动,但是预览框那边2列45列是白的,上面是满黄色的条,没波动啊
站长请帮帮我,我是第一次使用DeepFaceLab,到学习这一步时总会报错
Error: OOM when allocating tensor with shape[2048,1024,3,3] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[{{node training/Adam/gradients/model_1_1/conv2d_5/convolution_grad/Conv2DBackpropFilter}} = Conv2DBackpropFilter[T=DT_FLOAT, _class=[“loc:@training/Adam/gradients/AddN_25″], data_format=”NCHW”, dilations=[1, 1, 1, 1], padding=”SAME”, strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device=”/job:localhost/replica:0/task:0/device:GPU:0″](training/Adam/gradients/model_1_1/conv2d_5/convolution_grad/Conv2DBackpropFilter-0-TransposeNHWCToNCHW-LayoutOptimizer, ConstantFolding/training/Adam/gradients/model_1_1/conv2d_5/convolution_grad/ShapeN-matshapes-1, training/Adam/gradients/AddN_22)]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
我用 train 64就没事,用 128的也是会这样, 可能和显存啥的有关系吧
有大神知道為什麼訓練時preview只有SRC 和dst原畫面,最後一行只要黑色沒有合拼后的效果?
我也有这个问题