DeepFaceLab小白入门(4):提取人脸图片!
通过之前的几篇文章,你对换脸软件的使用应该有了一个大致的了解,也能换出一个视频来了。
此时,你可能会产生好多疑问,比如每个环节点点到底是什么意思,那些黑漆漆屏幕输出的又是什么内容,我换脸效果这么差,该如何提升?等等,好奇宝宝已上线,不搞明白睡不着。
接下来,我就把每个环节展开说一说。本篇文章主要说“人脸提取部分”。
开始之前先看两个目录。
DeepFaceLab 更目录如下。
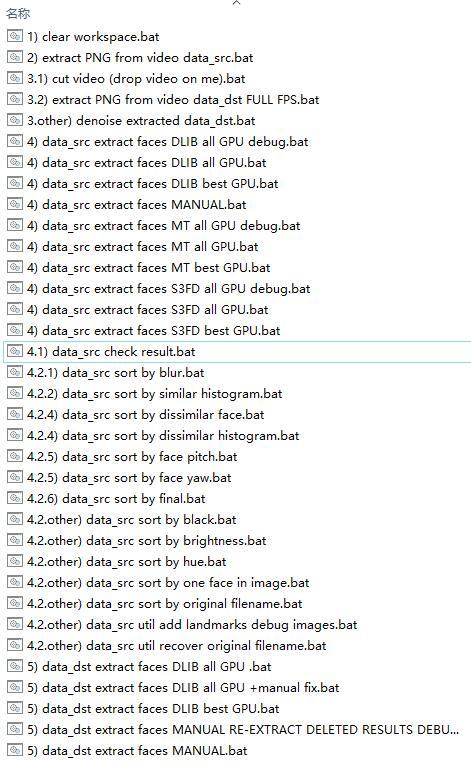
workspace工作目录如下
1) clear workspace.bat (清空项目)
这是一个用来初始化项目目录的文件,由于软件本身自带了一个workspace,所以你第一次使用的时候可点,可不点。点了之后,一个回车,界面如下。

2) extract PNG from video data_src.bat(视频转图片)
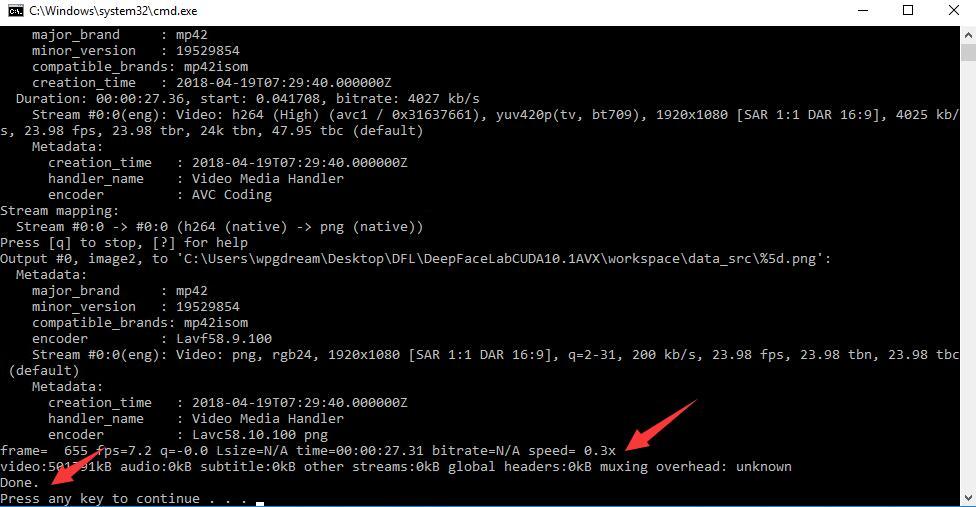
双击这个文件之后程序就开始运行,会出现一个提示。
Enter FPS ( ?:help skip:fullfps ) :
此时你可以直接回车,这样转换出的图片最多,你也可以输入一个20以内的数字,比如10,这样图片就会少一点,设置5 也可以。输入数字后回车即可。
注意:新版本多了一个jpg或png的选项。jpg会快很多,文件下小很多,png嘛图片信息会保存更多。
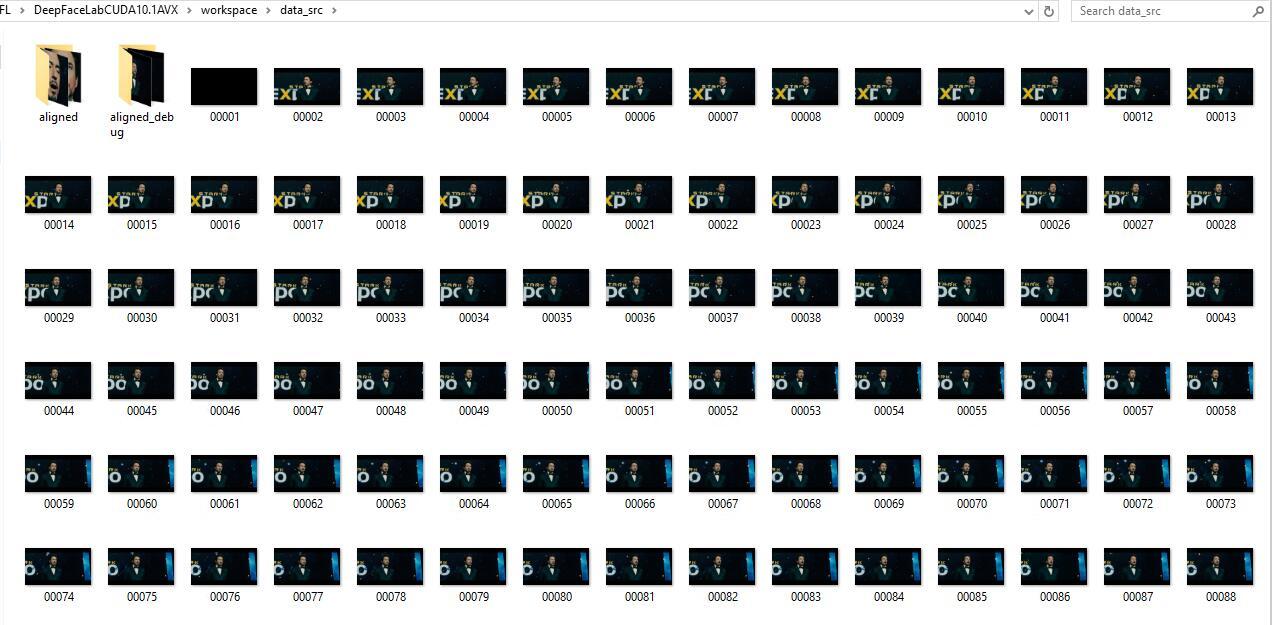
运行结束之后出现Done Press any key to continue。 此时在workspace\data_src目录中会出现好多图片,这些图片就是把视频一帧帧分解成图片了。
3.2) extract PNG from video data_dst FULL FPS.bat(视频转图片)
这一步和2)的原力是一样的,只是这次操作的视频是workspace\data_dst.mp4,而且默认是全帧率转换,转换完之后workspace\data_dst目录下面会出现很多图片。

4) data_src extract faces DLIB all GPU debug.bat(切脸)
这一步的目的是,把图片中的人脸提取出来。双击后自动运行,运行过程分三步走,不需要人为干预。
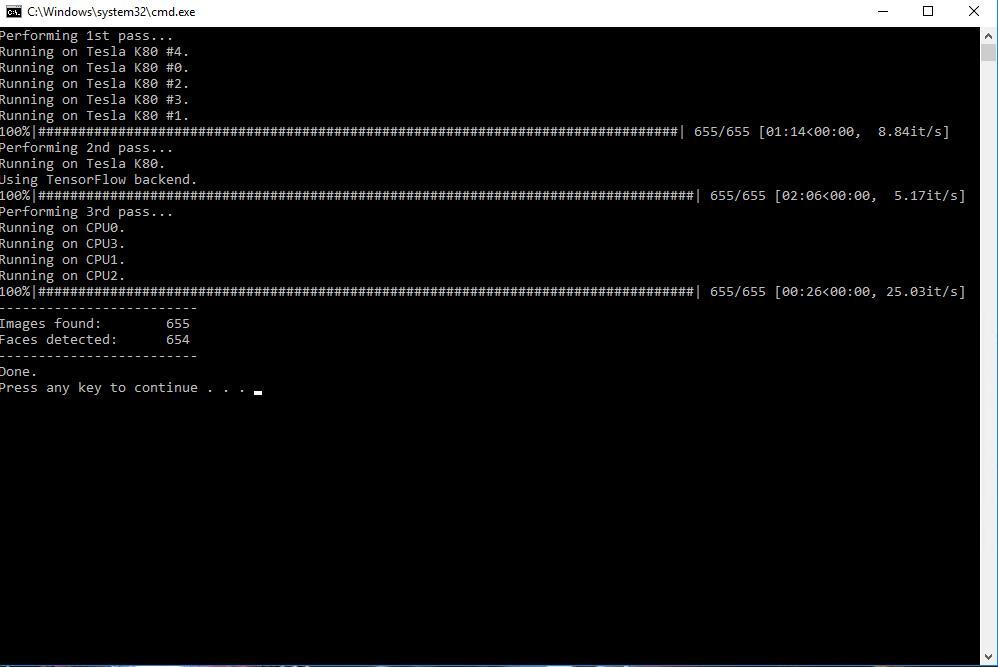
结束后会显示Images found 图片数量,Faces detected 检测到的人脸数量。
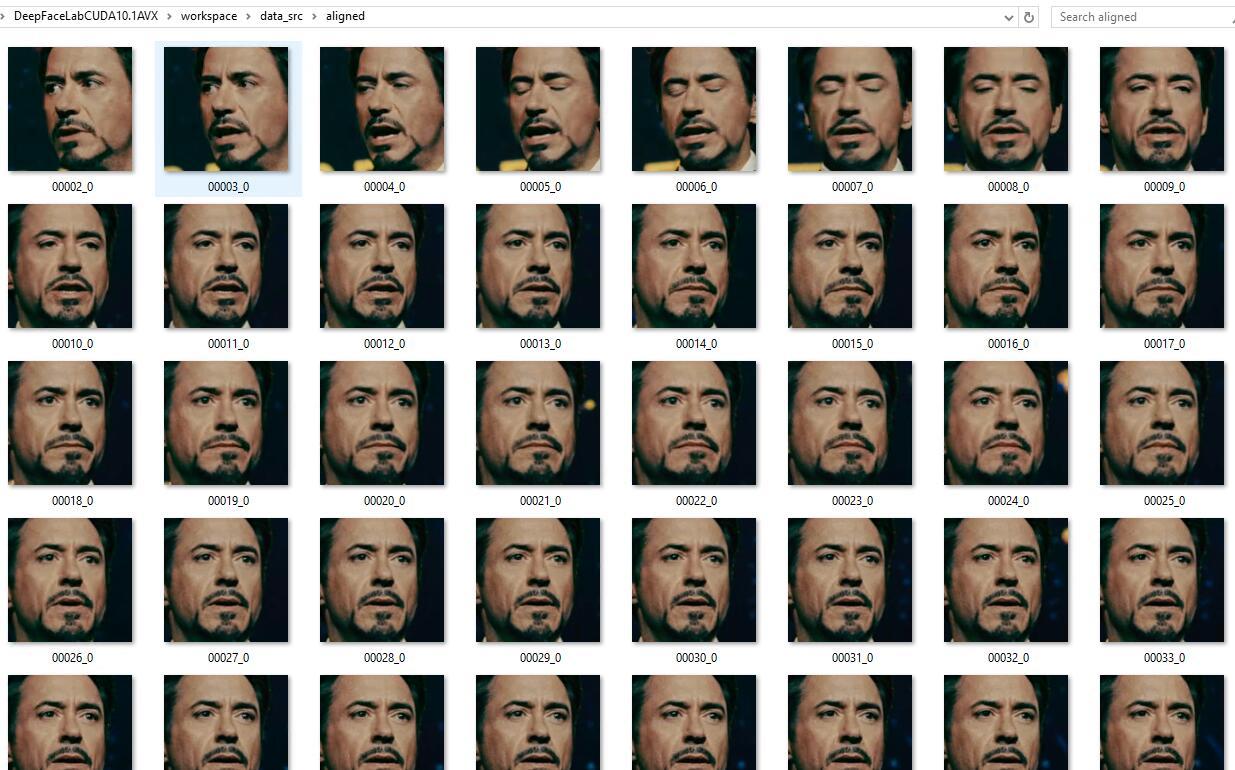
运行结束后,提取到人脸保存在workspace\data_src\aligned 目录。
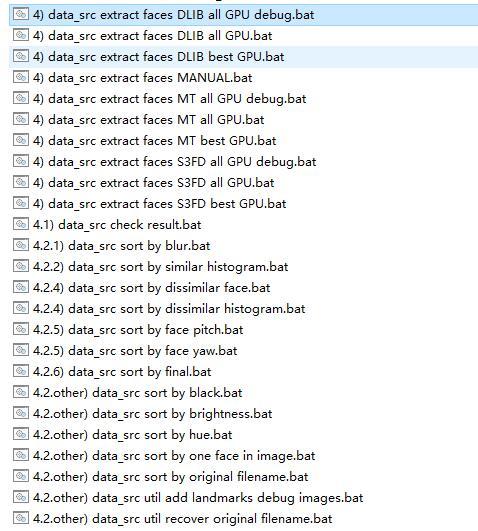
以4开头的文件非常多,但是并不想每个都点,主要包括了三个提取器DLIB、MT、S3FD,你只需要任选一个即可。差别主要是提取脸部的时间和效果有细微差别,S3FD是新添加的,据说性能比较好。注意:新版本已经没有DLIB可以使用MT或者S3FD.
4.1) data_src check result.bat (检查提取效果)
点击这个之后,自动打开一个看图软件,会帮你自动定位到workspace\data_src\aligned目录,在这里你可以把不清晰的,有遮挡,或者误提取的图片删除,留下清晰的高质量图片,这个会让你的模型质量更高,转换之后的效果更好。
4.2.1) data_src sort by blur.bat(排序)
4.2开头的都是排序工具,根据不同的特性进行排序,比如blur 只是更具清晰度来排序,这个你可以快速找到不清晰的图片删除,还有similar histogram根据相似度排序, face pitch 脸的俯仰,face yaw脸的左右偏移。 基本上只要用到这,排序的目的是去除劣质图片,筛选出优质图片。
5) data_dst extract faces DLIB all GPU .bat (提取脸部)
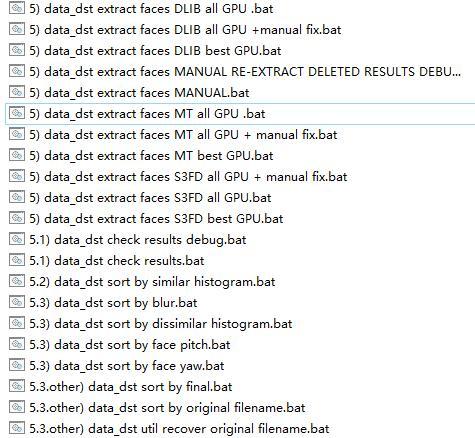
第五部和第四部的功能是一样的,只是一个提取src的脸,一个提取dst 的脸。与第四步不同是,添加了一个手动提取脸部的工具MANUAL RE-EXTRACT DELETED RESULTS DEBUG,还有默认生成aligned_debug。
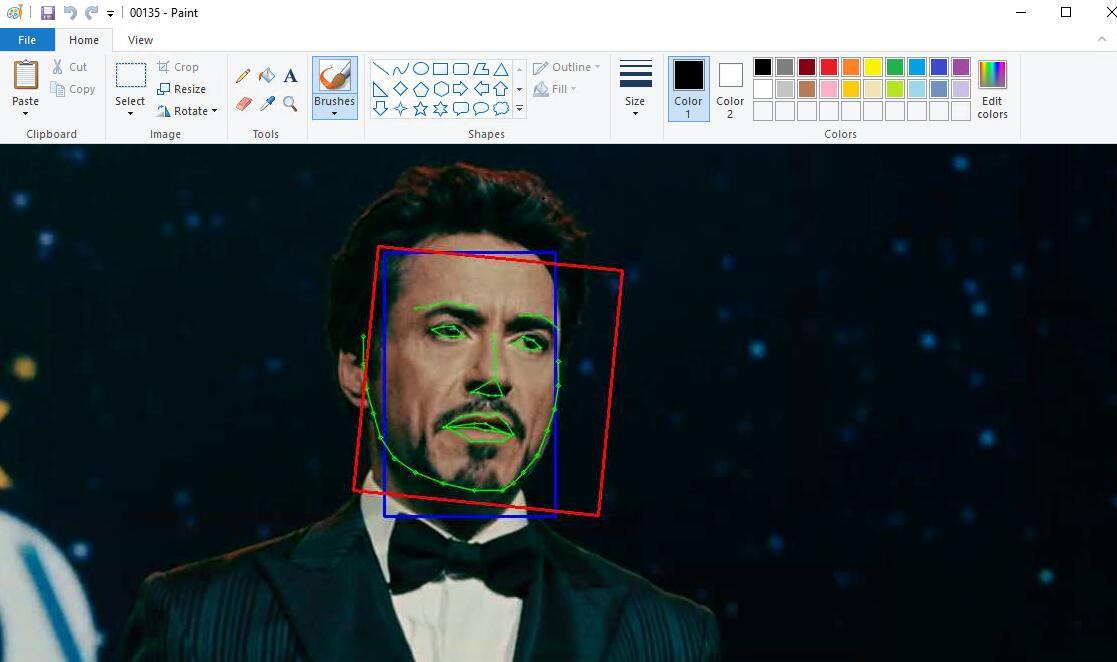
ps: 这里用了托尼老师的脸,实际情况应该是变形金刚男主的脸。
Debug中会有这样的图片,脸部有一个红色框和蓝色框,还有一个绿色的轮廓线。从上面这张图来看,这个提取效果是OK的,如果发现绿色线和脸部轮廓不贴合,那么就需要手动提取这张图片了。由于在后续合成的时候,程序会参考dst中debug的标线,所以修正这个错误很重要。
经过上面的步骤,dst和src的脸部提取就全部完成了。
这个步骤的关键点是保证脸部清晰,以及dst的轮廓识别准确,这样就为后面的步骤打下了坚实的基础
=======================================================================
扩展:
data_dst extract faces MANUAL RE-EXTRACT DELETED RESULTS DEBUG(手动提取脸图)
这一步的作用就是解决自动提取不准确的情况。使用前先删除DEBUG目录中标线有问题的图片,然后双击这个文件,进入后会出现预览界面,界面上有很多围绕脸部的点,轻轻移动鼠标或者转动鼠标就可以改变选中区域。觉得比较合适了就回车。进入下一张图片的操作。
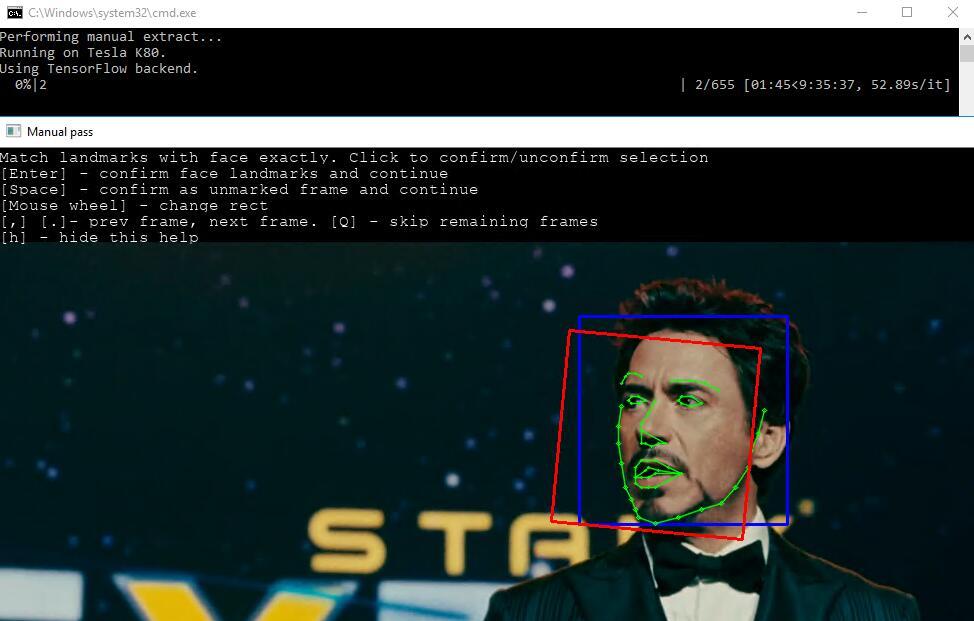
效果如上图,窗口上方有操作提示。
扩展:
如何换一组训练对象
如果你以及成功跑完所有环节,成功的把小罗伯特唐尼的脸放到了希亚·拉博夫的头上。此时你想换一个人玩玩,该怎么操作?
操作很简单,把data_dst.mp4和data_src.mp4换成新的视频,把model下面的文件全部删除,然后按上面在步骤再来一次即可。
如果你的视频太长,希望截取一部分,可以试下面的方法!
3.1) cut video (drop video on me).bat (视频截取转码,不懂的这一个不要点。)
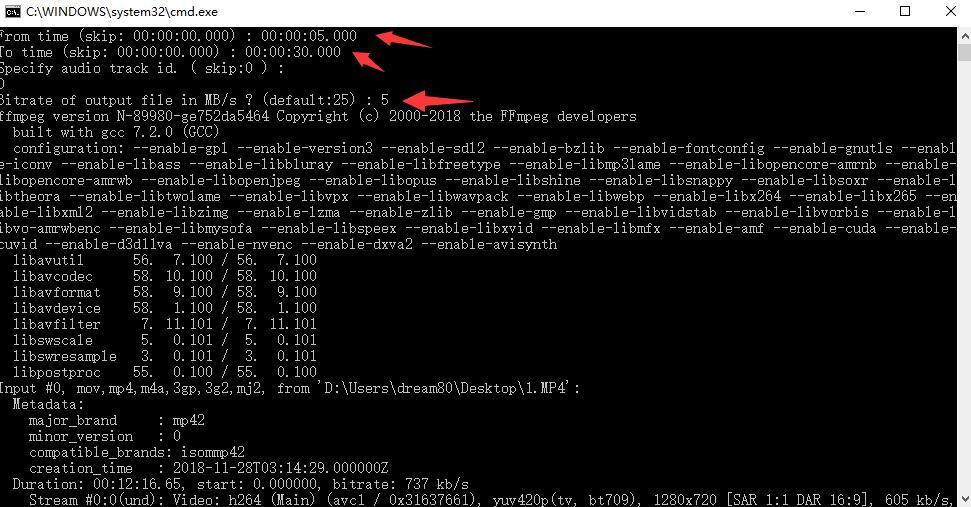
双击后,输入开始截取的时间点From time,回车,输入截取结束To time的时间点,回车,回车,输入码率 5,回车,等待结束出现done。
时间格式按照提示的来,码率一般不需要设置太高,设置成5足够了,你不输入直接回车也可以,默认值为25。默认情况截取的是workspace\data_dst.mp4这个视频,如果你想截取其他视频,可以把待截取的视频直接拖到这个文件上面。
PS:实际操作这文件不需要点,等到熟练之后,需要截取视频再来用这个功能。
后续步骤,请看:DeepFaceLab小白入门(5):训练换脸模型!
DeepFaceLab入门系列文章:


第四步提示ImportError:DLL load failed with error code -1073741795怎么解决
检查下驱动版本,是否大于418,否的话升级驱动。是的话就得另外找问题了!
intel UHD Graphics 620
Radeon (TM) 530
运行第四步的时候
usage: main.py extract [-h] –input-dir INPUT_DIR –output-dir OUTPUT_DIR
[–debug-dir DEBUG_DIR]
[–face-type {half_face,full_face,head,full_face_no_align,mark_only}]
[–detector {dlib,mt,s3fd,manual}] [–multi-gpu]
[–manual-fix] [–manual-output-debug-fix]
[–manual-window-size MANUAL_WINDOW_SIZE] [–cpu-only]
main.py extract: error: argument –debug-dir: expected one argument
出现这些代码 怎么解决阿?
问一下 scr截取的脸部 如果是侧脸的素材有必要保留吗 是会加重训练的负担还是干脆对训练没什么作用呢
是不是需要两只眼睛 两个眉毛 嘴 鼻子 都齐全
不是,侧脸没有遮挡的也要!
哦哦 收到 谢谢
各位大佬,提取人脸的时候出现了NVML Share Library Not Found要怎么解决?
站长,我看到有一些教程里说src除了使用视频截取的人脸,还可以自己加进去一些其他场景的人脸照片,这样可以拓展素材,增加准确率,请问这个说法正确吗?会不会加重硬件的负担?
看模型,H模型最好是同一个连贯的视频截取。SAE似乎可以加入不同颜色和光照。 加入图片并不会增加单次运算量,但是整体的loss下降可能会慢些,因为运算的图片更多,当然效果也会好些。
大大,你好,请问是只可以视频换视频的脸吗?可以用一张图片换一部视频里面的脸吗?如果可以的话请问应该怎么操作?
还有感谢站长的分享,谢谢!
图片换视频也可以的,但是一张图片不够,要多一点图片。因为软件需要提速人脸特征
请问如果只是保证最基本的大概需要多少张图片,然后如果是用图片的话是不是直接把图片塞到data_src文件夹下就可以了,替换新的视频是不是需要把名字改成范例视频的名字格式?
谢谢大大的解答
我觉得40张是能保证基本质量的
大神,请问提取原素材图片,怎么选择.jpg格式啊,在点第2)时我写了数字10按回车,就开始提取了,什么命令可以选择JPG?
提取的时候,出现jpg png提示的时候输入jpg回车!
大神,提取dst脸部的时候,有的图明明有脸部,但没有彩色标线标出来,也要一并删除吗?再手动提取?
4)运行出这个,怎么办
gpufmkmgr.pynvml.NVMLError_LibraryNotFound: NVML Shared Library Not Found
请按任意键继续. . .
更新驱动或者重装CUDA10.1
站長你好, 想請問一下
雖然說”表情角度光照”越豐富越好
但假設有一張圖, 原本人像就篇小
即使自動抓取也有抓到人臉, 但解析度有點糊(但不會太糊…吧)
這種情況, 這一張臉圖該留著還是砍掉?
src的话不要,dst的话要的!
不好意思再補問一下
我想先嘗試把SCR的Model訓練好
而目標DST只想要先嘗試換到1~2張”圖”就好(不用轉視頻)
這種情況, 是否還是要增加DST的張數?
還是DST只需要留我想嘗試的那1~2張?
同上再補充
看完了”Model”復用那篇說明
假設我拿到了一個已訓練好的Model
那麼此時DST是否還是要增加張數?
還是只需要留我想嘗試的那1~2張?
src dst都保持2000张以上比较好!
站长你好,请问跑图过程中出现 一连串“ibping warning:iccp:known incorrect SRGBprofile” 对结果影响大吗,有什么解决方法吗。谢谢,希望您能看到
大神,我在第四步中,Images found 图片数量正常,但Faces detected 检测到的人脸数量为0,请问该怎样修改?
提取人脸无论是 MT 还是 S3FD 各种模式到第第三步Loading提取人脸时只提取四五个人脸就闪退了,不知道什么情况 ,我的是2019.6.20的版本DeepFaceLabCUDA10.1AVX
没遇到过!
站长你好,在第四步中显示Exception: Unable to start subprocesses.怎么办?
第四部提取人脸时候最后出现这个Exception: Unable to start subprocesses.是怎么回事
提示是启动子进程出错,出现这个可能性很多,可以加群交流
脸部提取为零是什么原因?
我也一样,无论是fakeapp还是deepfacelab都卡在图片切脸,但是我后来4)试了一下用没有debug的那个就跑起来了
站長好
想問一下, 文章說dst的debug是合成的參考依據
那麼對於src來說, 如果臉有抓到, src的debug是否就不需要了?
SRC不用管Debug的
了解, 感謝解惑
是不是 3.2 没有运行
请问第四步出现这个怎么办?
Performing 1st pass…
Running on GeForce 820A. Recommended to close all programs using this device.
Exception: Traceback (most recent call last):
…….
File “imp.py”, line 243, in load_module
File “imp.py”, line 343, in load_dynamic
ImportError: DLL load failed: 找不到指定的程序。
Failed to load the native TensorFlow runtime.
See https://www.tensorflow.org/install/errors
for some common reasons and solutions. Include the entire stack trace
above this error message when asking for help.
这是TensorFlow版本问题。重新安装一下,或者尝试DeepFaceLab的其他版本。
請問站長 ,dst內的aligned 的臉部樣本,可不可以與src的臉部樣本一樣,只放700~1500張左右,並讓它開始進行訓練運算。直到要合成result視頻時,再把連續頭模及dst圖片丟進去,讓它進行結果合成。
不推荐src和dst放同样的素材!
站长,6要等多久啊
a卡 用的是DeepFaceLabOpenCLSSE版本
第四步骤时
file “D:\DeepFaceLaboOenCLSSE\_internal\python-3.6.8\lib\site-packages\plaidml\_init_.py”,line 1066, in devices
_setup_fail
file “D:\DeepFaceLaboOenCLSSE\_internal\python-3.6.8\lib\site-packages\plaidml\_init_.py”,line 1054, in _setup_fail
message, available>>
plaidml.exceptions.PlaidMLerror: No devices found. Please run plaidml-setup. The following devices are available:
b’opencl_amd_oland’
b’opencl_cpu.0′
该怎么办
有些字被吞了 再写一次
file “D:\DeepFaceLaboOenCLSSE\_internal\python-3.6.8\lib\site-packages\plaidml\_init_.py”,line 1066, in devices
_setup_fail “No devices found.” enumerator.invalid_devs
file “D:\DeepFaceLaboOenCLSSE\_internal\python-3.6.8\lib\site-packages\plaidml\_init_.py”,line 1054, in _setup_fail
message, available>>
plaidml.exceptions.PlaidMLerror: No devices found. Please run plaidml-setup. The following devices are available:
b’opencl_amd_oland’
b’opencl_cpu.0′
您好站长,请问dst提取出来的一些脸部上下颠倒的图是要删掉还是留着?
这种不要!
raise NVMLError(ret)
gpufmkmgr.pynvml.NVMLError_Unknown: Unknown Error
站长 请问1.提取脸部时 有的脸翻转方向不对, 和有时候全身也提取了影响训练吗 还是要删掉? 2.要是删的话是删aligned文件夹的图还是aligned_debug里的呢? 谢谢了
删aligned
请问4)提取成功 5)一直显示检测到0张图片是怎么回事儿,视频没有问题,拿成功的src视频都不行
4和5分别是提取src和dst的。你是不是没有Dst的图片啊
站长先生你好我没有任何的编程基础也能使用这项技术吗
可以的。这个事集成的好,无需编程!
你好请问如果一个视频中有多个人脸怎么进行对应的替换。有没有什么参数,要如何操作
Performing 1st pass…
Running on Generic GeForce GPU #0.
100%|################################################################################| 626/626 [01:11<00:00, 8.73it/s]
Performing 2nd pass…
Running on Generic GeForce GPU.
请问为什么会卡在这
你好,请问训练模型时出现这段代码怎么办?
Error: OOM when allocating tensor with shape[2048,1024,3,3] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[{{node training/Adam/gradients/model_1_1/conv2d_5/convolution_grad/Conv2DBackpropFilter}} = Conv2DBackpropFilter[T=DT_FLOAT, _class=[“loc:@training/Adam/gradients/AddN_25″], data_format=”NCHW”, dilations=[1, 1, 1, 1], padding=”SAME”, strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device=”/job:localhost/replica:0/task:0/device:GPU:0″](training/Adam/gradients/model_1_1/conv2d_5/convolution_grad/Conv2DBackpropFilter-0-TransposeNHWCToNCHW-LayoutOptimizer, ConstantFolding/training/Adam/gradients/model_1_1/conv2d_5/convolution_grad/ShapeN-matshapes-1, training/Adam/gradients/AddN_22)]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
Traceback (most recent call last):
File “D:\1DF\workplace\dfl\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\mainscripts\Trainer.py”, line 78, in trainerThread
loss_string = model.train_one_iter()
File “D:\1DF\workplace\dfl\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\models\ModelBase.py”, line 358, in train_one_iter
losses = self.onTrainOneIter(sample, self.generator_list)
File “D:\1DF\workplace\dfl\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\models\Model_H64\Model.py”, line 85, in onTrainOneIter
total, loss_src_bgr, loss_src_mask, loss_dst_bgr, loss_dst_mask = self.ae.train_on_batch( [warped_src, target_src_full_mask, warped_dst, target_dst_full_mask], [target_src, target_src_full_mask, target_dst, target_dst_full_mask] )
File “D:\1DF\workplace\dfl\DeepFaceLabCUDA10.1AVX\_internal\python-3.6.8\lib\site-packages\keras\engine\training.py”, line 1217, in train_on_batch
outputs = self.train_function(ins)
File “D:\1DF\workplace\dfl\DeepFaceLabCUDA10.1AVX\_internal\python-3.6.8\lib\site-packages\keras\backend\tensorflow_backend.py”, line 2715, in __call__
return self._call(inputs)
File “D:\1DF\workplace\dfl\DeepFaceLabCUDA10.1AVX\_internal\python-3.6.8\lib\site-packages\keras\backend\tensorflow_backend.py”, line 2675, in _call
fetched = self._callable_fn(*array_vals)
File “D:\1DF\workplace\dfl\DeepFaceLabCUDA10.1AVX\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py”, line 1439, in __call__
run_metadata_ptr)
File “D:\1DF\workplace\dfl\DeepFaceLabCUDA10.1AVX\_internal\python-3.6.8\lib\site-packages\tensorflow\python\framework\errors_impl.py”, line 528, in __exit__
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[2048,1024,3,3] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[{{node training/Adam/gradients/model_1_1/conv2d_5/convolution_grad/Conv2DBackpropFilter}} = Conv2DBackpropFilter[T=DT_FLOAT, _class=[“loc:@training/Adam/gradients/AddN_25″], data_format=”NCHW”, dilations=[1, 1, 1, 1], padding=”SAME”, strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device=”/job:localhost/replica:0/task:0/device:GPU:0″](training/Adam/gradients/model_1_1/conv2d_5/convolution_grad/Conv2DBackpropFilter-0-TransposeNHWCToNCHW-LayoutOptimizer, ConstantFolding/training/Adam/gradients/model_1_1/conv2d_5/convolution_grad/ShapeN-matshapes-1, training/Adam/gradients/AddN_22)]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
我也是
请问站长,在data_src视频的选择上,是否单一某场景的视频比复合场景的视频(比如混剪视频)的表现更好呢?
单一场景合成效果很稳定。 复合场景可能会出现问题。
我第6步搞到一半就出现这个停了怎么办啊。。。求助大佬
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
Done.
OOM,一般是配置不够,具体来说就是显存不够。调低参数。
楼主,我在做第6步的时候出现问题
代码:Running trainer.
Loading model…
Model first run.
Enable autobackup? (y/n ?:help skip:n) :
n
Write preview history? (y/n ?:help skip:n) :
n
Target iteration (skip:unlimited/default) :
ValueError: No training data provided.
请问是不是我电脑显存太小了还是其他的?
缺少素材!
站长好,我在第四步出现了这段话,重装后试了很多次都是这样,不知道什么原因,请您指教
Traceback (most recent call last):
File “F:\DeepFaceLab_NVIDIA0601\_internal\DeepFaceLab\main.py”, line 318, in
arguments.func(arguments)
File “F:\DeepFaceLab_NVIDIA0601\_internal\DeepFaceLab\main.py”, line 42, in process_extract
force_gpu_idxs = [ int(x) for x in arguments.force_gpu_idxs.split(‘,’) ] if arguments.force_gpu_idxs is not None else None,
File “F:\DeepFaceLab_NVIDIA0601\_internal\DeepFaceLab\mainscripts\Extractor.py”, line 780, in main
device_config=device_config).run()
File “F:\DeepFaceLab_NVIDIA0601\_internal\DeepFaceLab\core\joblib\SubprocessorBase.py”, line 219, in run
raise Exception ( “Unable to start subprocesses.” )
Exception: Unable to start subprocesses.
请问站长第四步这样是怎么回事?谢谢
Traceback (most recent call last):
File “F:\DeepFaceLab_NVIDIA0601\_internal\DeepFaceLab\main.py”, line 318, in
arguments.func(arguments)
File “F:\DeepFaceLab_NVIDIA0601\_internal\DeepFaceLab\main.py”, line 42, in process_extract
force_gpu_idxs = [ int(x) for x in arguments.force_gpu_idxs.split(‘,’) ] if arguments.force_gpu_idxs is not None else None,
File “F:\DeepFaceLab_NVIDIA0601\_internal\DeepFaceLab\mainscripts\Extractor.py”, line 780, in main
device_config=device_config).run()
File “F:\DeepFaceLab_NVIDIA0601\_internal\DeepFaceLab\core\joblib\SubprocessorBase.py”, line 219, in run
raise Exception ( “Unable to start subprocesses.” )
Exception: Unable to start subprocesses.
我很好奇如果使用同一人物的一系列图片组成的视频来代替data_dst或data_src的话,最后执行完(7)convert步骤之后的效果会怎么样?
Performing 1st pass…
Running on Generic GeForce GPU #0.
Exception: Traceback (most recent call last):
File “C:\Users\老鱼\Documents\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\joblib\SubprocessorBase.py”, line 58, in _subprocess_run
self.on_initialize(client_dict)
File “C:\Users\老鱼\Documents\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\mainscripts\Extractor.py”, line 49, in on_initialize
nnlib.import_dlib (device_config)
File “C:\Users\老鱼\Documents\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\nnlib\nnlib.py”, line 538, in import_dlib
nnlib.dlib.cuda.set_device(device_config.gpu_idxs[0])
RuntimeError: Error while calling cudaSetDevice(dev) in file D:/DFLbuild/dlib/dlib/cuda/cuda_dlib.cu:20. code: 35, reason: CUDA driver version is insufficient for CUDA runtime version
Traceback (most recent call last):
File “C:\Users\老鱼\Documents\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\main.py”, line 195, in
arguments.func(arguments)
File “C:\Users\老鱼\Documents\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\main.py”, line 33, in process_extract
‘multi_gpu’ : arguments.multi_gpu,
File “C:\Users\老鱼\Documents\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\mainscripts\Extractor.py”, line 586, in main
extracted_rects = ExtractSubprocessor ([ (x,) for x in input_path_image_paths ], ‘rects’, image_size, face_type, debug, multi_gpu=multi_gpu, cpu_only=cpu_only, manual=False, detector=detector).run()
File “C:\Users\老鱼\Documents\DeepFaceLabCUDA10.1AVX\_internal\DeepFaceLab\joblib\SubprocessorBase.py”, line 179, in run
raise Exception ( “Unable to start subprocesses.” )
Exception: Unable to start subprocesses.
请按任意键继续. . .
请问这是什么问题?
升级驱动!
您好,请问一下我卡在第五步,从dst素材中提取人脸失败,最后aligned文件夹中也没有文件
是不是没有data_dst.mp4这个文件
请问l楼主,如果我有一堆目标图片而非视频,我可否直接用这些图片而不用从视频中解帧然后提取头像呢?
完全可以!放到data_src或者data_dst