DeepFaceLab进阶:模型复用,半小时出好作品的秘密!
这是世界上没有什么比时间更可贵的事情了。而玩换脸软件恰恰是一个非常耗费时间的事情。无论筛选素材,还是提取人脸,还是人脸替换都费时间,其中最费时间的自然是训练模型。
注意:虽然小白也可以复用别人的模型,但是模型复用这个操作更适合已经看完入门教程并且已经熟悉软件使用的朋友。
*训练一个模型到底要多久?
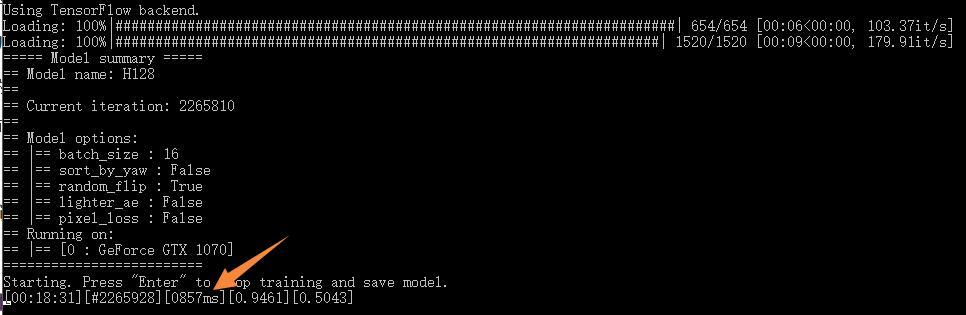
举个栗子,假设你的设备为GTX 1070(0.857s), 使用的模型为Model=H128 , 批量大小为Batch_size =16, 训练的迭代次数为Iter=200万。
那么,你需要的时间大概为Time= 2000000*0.857/3600=476小时=19.8天
虽然那些号称一个百万模型需要1000个小时的都是骗子,但是练模型的过程确实非常费时间。
最关键的是,大多数的模型并不是一次成功的,新手往往要尝试无数次才能出好的效果,所以这个时间是非常恐怖的。
为了验证一个参数或者一个优化的想法,我们往往需要好多天。
*如何缩短模型的训练时间?
那么问题来了,练模型那么久,有没有速成的方法?刚开始没有人知道,但是随着大家的摸索发现了一些规律:模型是可以复用的。 通过复用,我们可以极大的减少训练的时间。
这个“复用”的意思就是我用A和B训练了一个模型,下次训练C和D的时候不用从零开始,而是可以在A和B训练的模型基础上训练,这样就极大的缩短了训练的时间。
假设我用半个月时间训练了一个张三和李四的200万的模型,然后我想要把王五的脸放到赵六身上,此时,我不需要再训练半个月,我只需要训练几十分钟到几个小时即可。
这个时间压缩的是不是非常厉害,简直就是“救命”一般,这是一个让人兴奋的结论。
模型复用的几种情况
模型复用主要主要可以分为两种情况
- 专人专用
- 多人复用
所谓专人专用,其实就是SRC不变,Dst变。 举例来说,我练了一个张三和李四的模型,然后我想换张三和王五了,此时我就复用张三和李四的模型,这种情况下训练张三和王五的模型会非常快,几分钟到几十分预览图就非常清晰了。专人专用这种情况那,你其实是复用了SRC的素材和模型。
所谓多人复用。其实这种才是魅力最大。举例说明,我练了一个张三和李四的模型,然后我想要换王五和赵六,此时,我只需要把张三和李四的模型拿来继续练即可。 这种情况下,其实是换了SRC和DST,需要继续训练的时间会长一点,一般几个小时。
专人专用出效果非常快,相似度也很高,但是为每个人训练一个模型,这个时间消耗也不少。
多人复用出效果相对慢些,有四不像的风险,但是复用性极高,能最大限度节省时间。
当然,所有模型复用的优势,都取决于这个被拿来复用的模型的质量。并不是说,随随便便练个几百万,就无敌了。炼丹其实是有很多部分构成的。素材,参数,时间,火候….
如果模型混入了不良素材,很难剃除,最终导致的结果就是合成视频会出现各种奇怪的现象,这种现象通过继续训练也很难解决。
*模型复用的具体操作
说了那么多,实战最重要。 核心思想就:换Model下面的文件。
我这里以软件自带素材为例说明。假设我们已经有了如上图的文件,并且已经将视频转换成图片,从图片中提取了头像。正常情况下就开始从零开始训练模型。此时我们突然“搞来了”一个200万的优质的H128模型(俗称仙丹),你就可以根据以下步骤来操作。
1.复制模型文件
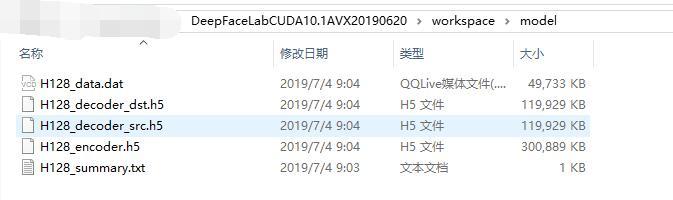
我们的操作就是把这个模型放到model目录。如果之前有这些文件你可以先备份或者直接覆盖。
2. 开始训练模型(回炉)
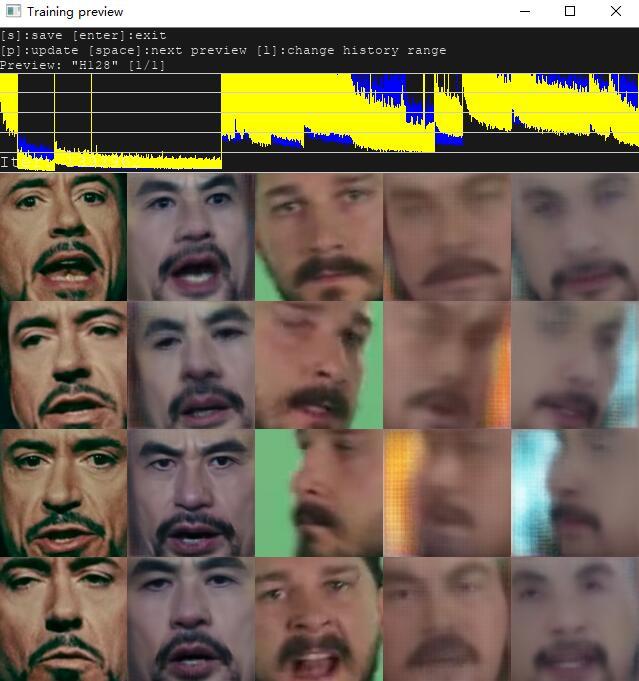
点击6) train H128.bat 开始训练,参数全部默认。从上图可以看出,刚启动的时候,第二列和第一列不是同一个人,但是五官已经非常清楚。第四列和第五列都比较模糊。
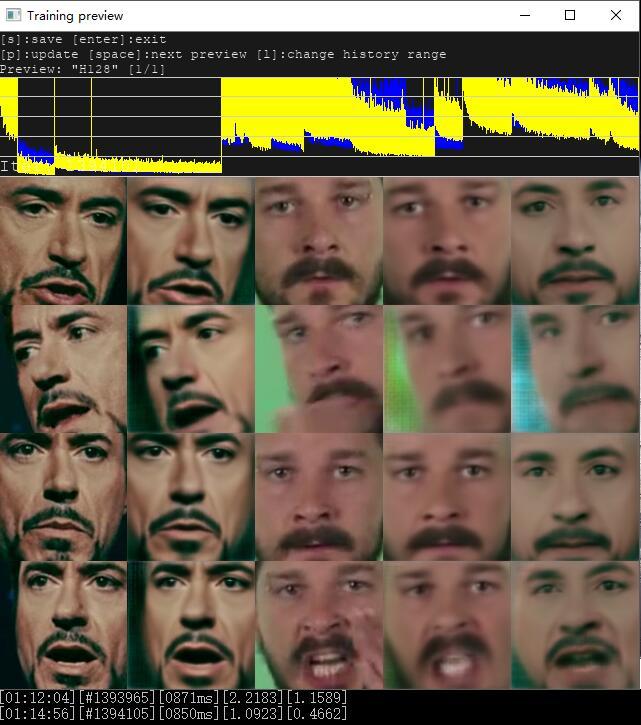
大概三分钟后,鼠标移到预览图上,按键盘p键刷新预览图,此时头像已经比较清晰。第一列和第二列,第三列和第四列都为同一个人。第五列似乎谁都不像,但是轮廓也是比较清楚了。
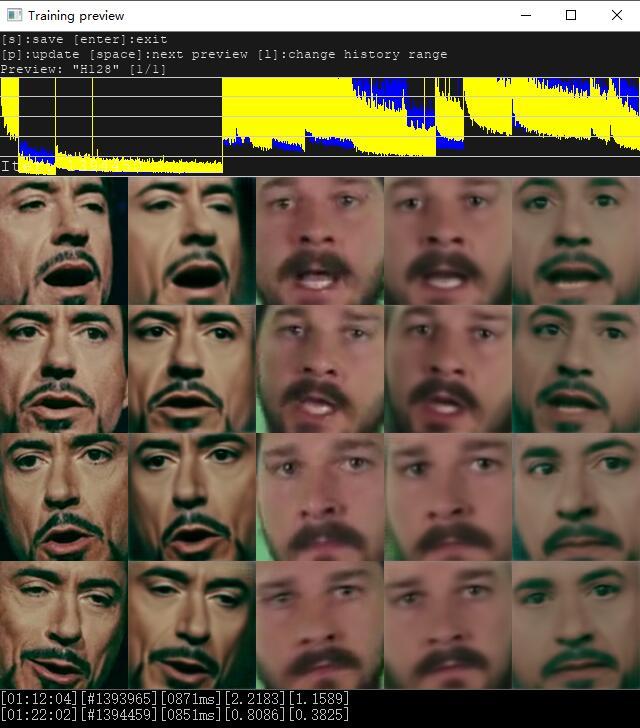
大概10分钟后,效果如上图,第2,4,5列逐渐清晰,第五列的人脸逐步向第一列靠拢。 因为我这里相当于src和dst全部换了,所以回炉时间可以适当长一点,效果会更好。

10分钟后,我突发奇想,我又要换人了。比如把对象换成迪丽热巴和杨颖baby。
(一般不建议这么干,建议从上面的基础模型开始练,不要在换了一个之后的基础上再换)
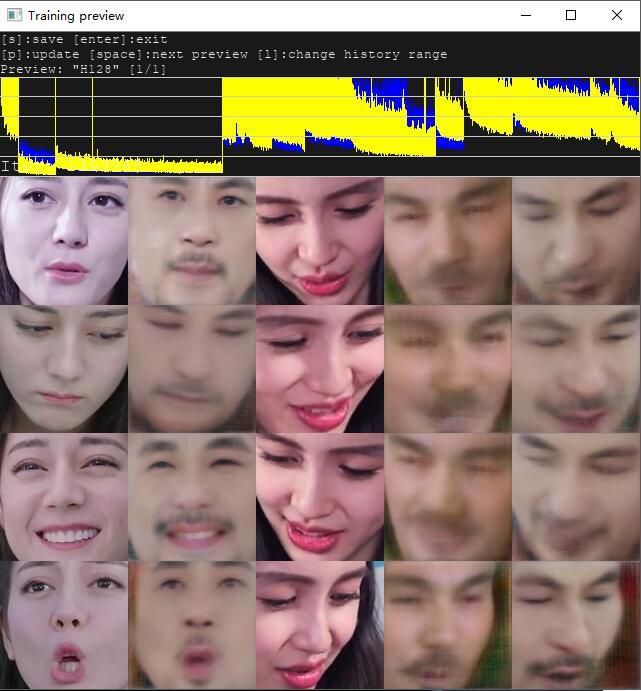
重新点击 train H128.bat 开始训练。 刚启动依旧是模糊的。在几秒后,二话不说来个P,预览图里面变成了下面的样子。
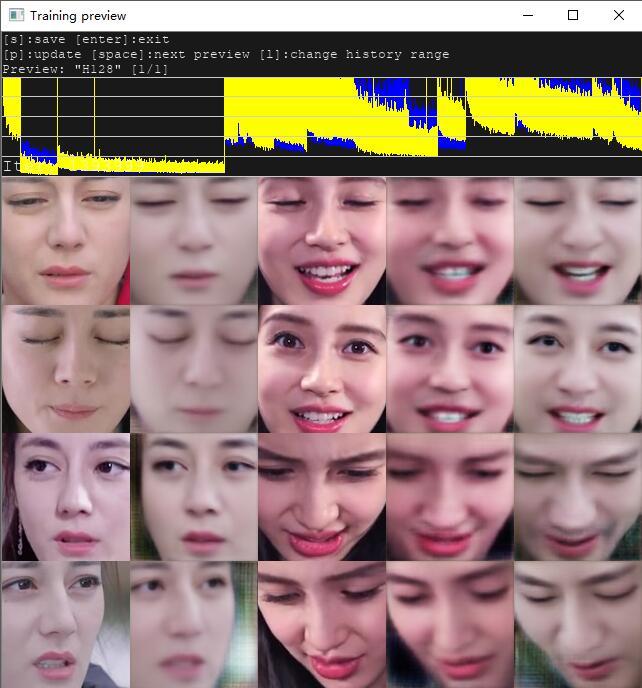
是不是变魔法一般,原先需要几天几十天完成的事情,现在只要几秒钟。
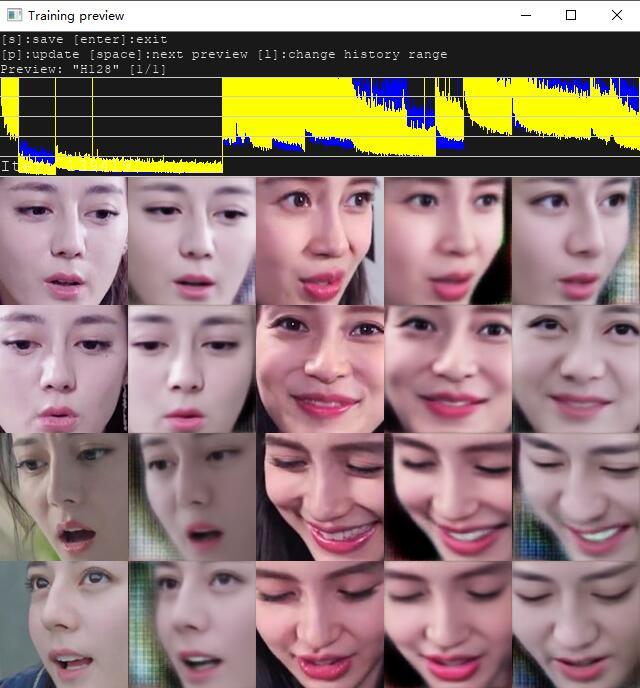
几分钟后,此时基本清晰,第五列也能分辨出来到底是谁。 接下来为了稳妥起见可以让它练个几个小时。
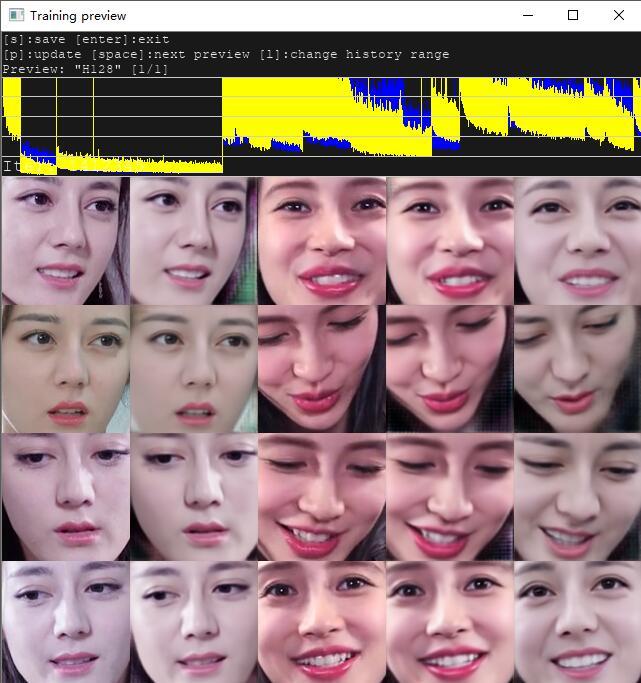
几个小时后~~!
3. 开始转换
训练一段时间后就可以点击7) convert H128.bat和8) converted to mp4.bat 进行转换合成。
到这一步,模型复用就完成了。
=========================================================
当然这其中还会有非常多的细节,但是整体的过程就是这样。
一个优质模型,可以让你省去很多时间,经历,设备损耗。
时间啊,时间,真是过得快啊,从晚上8点开始写,现在已经快凌晨2点了。
生命可贵,禁不起浪费,希望我的这篇文章能为大家剩下宝贵的时间。
==========================================================
有需要现成模型的可以找:【哈皮哥QQ/WX:851296674】



好可怕!!! 期待更新!
所以能不能吧这个优质模型分享粗来呀~~~~楼主好人~~
你这好人卡发的……我不知该如何是好!
楼主,我想要DeepFaceCUDA10.1AVX20190620这个版本,不知那里可以下载,或者网盘分享一下撒。谢谢。
这个一直有分享哦,网页下载板块就有,就是关注公众号“托尼是塔克” 然后发送dfl 就是620版本全套安装文件。
这个页面之前是走丢了吗
請問訓練到一半,發現有某個表情不太自然,再加入新的影片素材,是可行的嗎?
可以,但是不会立竿见影,也许要很久很久之后见效
那么问题来了,仙丹在哪呢(手动滑稽)
我弱弱的问一下,模型能不能分享一下。。。。。。
抱歉,模型是需要时间、设备、经验才能练成的,不会分享。我已经把大部分技术经验都分享出来了,模型你们可以自己训练,或者通过其他途径去获取! 我知道大家都是求个方便,但是每一个人为了到达彼岸,都需要自己去努力和付出。
精辟!
ok的,而且我手贱发了两条。。。。。。无视了吧
谢谢博主呀。刚刚入门,受益匪浅。
小白来理解下:替换掉换脸的两个视频,然后切图,切脸。在训练前,把之前的模型 model 文件夹复制到\workspace下,然后开始train 对吧。
正确
请问一下,有了SRC模型文件之后是不是就不需要图片了,你说的这个单人复用我可不可以在你发的那个谷歌云计算上算完之后放到我电脑上玩单人复用?
最近在研究各类gan的模型合并,今天正好看到这个贴,回答一下,以备其他兄弟复问:data_src下的aligned是什么呢?是你训练模型的物料,素材集,可以替换,更新,但,哈哈哈,不能没有。同样道理,data_dst下的aligned也是必须物料,可以换,比如,你换了个目标视频,那就换了这个文件夹下的内容,但不能没有。模型文件夹下的h5是啥,模型呗,这些文件不能没有,一上来没有,训练后就有生成了,反复训练以及使用,这是灵魂。合并生成视频需要整个data_dst的文件夹,所以,这个文件夹下的图,除非你换新视频,否则这些图不要动。
大佬,群里有模型素材吗?
我想问已有一个专人训练到0.1的库后,想再添加一部分该人src的aligned人脸素材继续训练,是直接复制到该库aligned文件夹训练还是说要改下它们的编号后再复制,因为原aligned人脸编号和后来添加的aligned人脸编号部分是一样的。还是说不能继续添加src素材训练了?
請問版主 如果模型一直使用”多人複用”最後可能使臉型變得四不像嗎?
我用谷歌云训练好像不能用以前的模型啊,是不是还要deepfacelab-colab这个文件夹的东西要保存着。。。我删了
这是不可能的,无论是那个gan,DFL这方面做的一流,你操作出了问题。colab是tony大为了广大新人做的最棒的东西,你删了,还咋整。哈哈,这个文件夹和工作space是并列的两个文件夹,路径都给你设置好了。只要直接第六步,唯一有小问题的是,tony在第六步写了unzip workspace,在这一步再写这句有待商榷,因为哪天新人不注意,一个手贱,完蛋了。
多人复用是src和dst模型文件都要换么?如果已有一个模型,要换目标人物dst,需要重新抽取dst人脸对吧,dst模型文件删不删?
不删
我来给托尼大做个补充,模型是啥,模型是机器学习的算法的函数集。在DFL的任何一种模式下都有三个模型,一个编码器模型,两个解码器模型。这三个h5,你都不能删。举例,咱要做一个钢铁侠出来,咱有台3D打印机,咱给了这台打印机输入了钢铁侠的照片,哗啦啦,出来了,过两天咱想做蜘蛛侠了,咱用得着换打印机吗?这台机器就是咱的模型。
如果要訓練模型能用复用的方式持續累積次數來訓練不同人嗎?
例如一个百万但過程換了多組人了。
可以啊,分享十个妹子给楼主就行了。
大神你好,謝謝你分享這個思路,這極大縮短了每個模型的訓練時間
正打算回去練他個一練,弄出個高質量的Model出來,補足自己素材不足的問題
也問一下還沒實驗的問題:
透過各角度、光影十分豐富的資料Source A和Dest B去練出高質量Model後,
將Dest B換成Dest C,其中Dest C素材的面相不足(缺乏像低頭、側臉…等資料)
高質量Model內的資料能夠補足Dest C的不足嗎?
練完後的Source A to Dest C新Model,
在低頭、側臉這些的轉換上會保留Dest A的特性、或能透過局部的Dest C資料去演算出來呢?
謝謝!
不知道是我理解错了还是你问错了,dst是不存在面向不足的吧。比如dst只有正脸和左脸,虽然从全脸的角度说是缺乏了右脸但由于dst本来就没有右脸那么转换成片的时候也不需要右脸了,何来面相不足一说呢?如果是说src的面相不足问题的话,我可以回答你是“会补足”的。我在网上下载了一个500万迭代的模型,src是用了几乎是同一角度的200张照片,最终合成的效果跟本人相似度是很高的。但是由于原模型的src跟替换的src都是年轻女性且相貌有一定相似度,所以我尚未确定这个实验结果足以充分证明其补足性,但可作参考。
感謝你的經驗分享,那確實是可行的
是我理解錯,對dst和src定義想反了
我来补充下,数据集严重不足是不行的。任何模型都不存在无中生有,它都是通过数据集的反复生成,验证,从而来寻找目标函数。这个寻找的过程,叫训练。当我们在一个已经拥有拼凑图形信息,也就是寻找函数能力极强的模型时,你输入少量重复照片,它一样能完成信息拼凑,这就好比,你给一个罪犯特征还原的老警察,几句简单描述,他就给你画出那个人,且八九不离十,但给一个没训练过的新警察,说一堆,甚至给出一张接近的图,让他深入画细些,他还是不行。老警察和新警察的区别就是过往受过的训练量,接受过的数据量。模型是啥,警察就是模型。我们教孩子学打球,孩子起初不会打,我们让他看,让他跟着人打这个过程就是训练,孩子就是模型,孩子投进篮球,拿下各种成绩,被拍成视频等等就是输出result结果。200张同一角度,是因为你拥有500W迭代的神器。那是可以卖钱的,哈哈哈。上面那个兄弟的问题,srcA,也就是最终你想在生成的视频上看到的那张脸,能给多足给多足,清晰度,能有多高给多高,原始头像,能有多大给多大。dst是你最终视频生成的脸部表情人物动作的参考集,在DFL这个工具下,不存在生成参考集以外的表情和肢体,参考集有多少帧,做了那些动作,说了哪些话,出的是什么表情,最终生成的视频就是这些,只是用了你src的那张脸的脸部特征。所以jerry才会说dst不存在不足这个逻辑。那什么情况下,dst会不足?逆向生成。也就是你打算把dst当成src用的时候。
既然来了,就再帮伙伴们做个小普及:1,学习是渐进的。你能够要求一个不会打球,毛还没长的娃娃,明天直接去参加NBA选秀吗?不能。所以,训练模型必须是一步步教它。从简单的相似模仿到创造。刚开始训练,src和dst两张脸,尽可能选择接近的,相似的,表情、角度,光源也可以接近些。数据集的量3:1,也就是说,src图1500,dst500张。我个人经验,以现在最新版本+colab K80,12小时,loss就刷进0.2,也就是说,你已经能看效果了。2,剔除杂质,你要知道,你叫小孩打球,一上来就教了野路子,小孩学了坏毛病,这辈子能改吗?很难。所以,训练模型,一开始的src是必须精选的,兄弟们,这个时间不怨,后面孩子的好习惯养成了,咋玩咋顺。3,大家看到ZAO,说人8秒就ok了,咱8周,咱这个是不是不行啊。呵呵,那是因为你没看到,脸部生成技术刚出炉时,人用全世界最好的服务器,排排连,然后疯狂训练模型(不止一个模型)N个月。4,那为啥,人只要一张照片,咱搞死,这里就说到算法了,你们每个人都被要求拍正面照或接近于正面的高清才能通过,这张照片是特殊的,是用来对齐目标dst的正面的,1对1模型。当1对1完成后,他们去掉了src_h5的训练,也就是说,最丫的花时间的步骤省略了。————最后说一句,各大公司,以及不少大神不愿意拿出这个算法,不是因为做不到,是因为真的有危害,虽然,早晚烂大街。ps:..此处内容太牛逼已隐藏..(zao我就不说了,那是随便破的。)。自打那天起,我意识到任何技术都必须在社会环境条件成熟的情况下拿到市场上做应用,环境不成熟前,绝对不能。
再补充一个:双号24小时连刷。colab有12小时限制:解决的方法是两个gmail号,最好三个。然后共享主号的主目录给另外两个号,然后,联机修炼。我以前和托尼大一样,是付钱给谷歌云阿里云的。哈哈哈。
刚开始我也是玩colab啊,哈哈,所以才写了那个脚本。
老大你真心的赞,我觉得你的耐心和原作者有得一拼,让广大爱好者能够逐步深入这个领域。这台重要了。因为未来属于人工智能,不是国内假paper骗补那种,是真正的人工智能,我们一路关注,期待各种新算法的合并与进步。我觉得按照 iperov老兄的死磕劲,离全身fake不远了。哈哈哈,回头,你有的忙啦。
另外,你的博超级棒,知乎的我也关注了,你有一回推荐了牛逼的超分辨工具,那是我用过的最棒的图形界面超分辨,省去了我们玩命磕码的时间。真心感谢。
这个联机时都安装上dee共享主目录然后一块练模型吗?
三个账号都安装dee然后三个账号一块联丹就可以了吗?
同样的视频素材跑A脸几十万,然后直接那这个几十万跑B脸,视频素材不变,但是合成出来的图片清晰度永远没有原A跑出来的清晰
找到一颗140w的仙丹…以前电脑只能走h64 现在h128 batch2 慢慢走好素材真的几小时就效果不错了..真心牛
能分享下仙丹吗,有偿也行
COLAB有升級?
這兩天常開到Tesla P100-PCIE-16GB
== Model name: SAEHD ==
== ==
== Current iteration: 359128 ==
== ==
==————- Model Options ————–==
== ==
== sort_by_yaw: False ==
== random_flip: True ==
== resolution: 128 ==
== face_type: f ==
== learn_mask: True ==
== optimizer_mode: 1 ==
== archi: df ==
== ae_dims: 512 ==
== ed_ch_dims: 21 ==
== face_style_power: 0.0 ==
== bg_style_power: 0.0 ==
== apply_random_ct: False ==
== true_face_training: True ==
== clipgrad: False ==
== batch_size: 8 ==
== random_warp: True ==
== ct_mode: none ==
== ==
==————— Running On —————==
== ==
== Device index: 0 ==
== Name: Tesla P100-PCIE-16GB ==
== VRAM: 16.00GB ==
== ==
==============================================
Starting. Press “Enter” to stop training and save model.
[01:28:35][#360079][0775ms][0.1636][0.1051]
[01:43:40][#361040][0769ms][0.1619][0.1062]
[01:58:43][#362006][0774ms][0.1614][0.1057]
对显卡升级了,p100还是有点强的。
感謝老大的分享.受益良多.
最近有看到聲音也可以深度學習.不知道老大有沒有研究.
能不能也寫一個google colaboratory的腳本.讓小弟也可以玩玩聲音的訓練.
詢練好的影片 + 訓練好的聲音 = 完美 .讚
再次感謝您的付出.
看了下效果不是很好,所以没有去研究。
仙丹回炉太nb了,我的流程是这样,用质量比较好的素材a和b训练,这里面包含的表情和角度比较丰富,训练10天之后,基本达到一个不错的效果,这时候套用C 和D,C作为scr我只有一些图片,没有很完整的表情和角度,但是训练一个小时左右就基本上可以用了,即使没有对应的表情也不会穿帮。
原來還有這個原理.感謝分享
也不是万能啦,复用的时候如果实在素材太少,比如说C没有开口大笑的表情,这时候遇到开口笑的表情就会长得像之前炼丹用的A。如果A和C比较像的话就会比较难看出破绽。如果长得比较不一样的话,表情一多可能看起来有点像变脸哈哈,一会儿像C一会儿像A
恩.好的素材還是很重要.
有時.預覽看得好好的.合成後卻糊糊的.呵呵.
不過.小弟知識有限.也玩不了很深入.目前出的東西都只是”很像”而已.哈
現在倒是想玩玩聲音.不曉得大大知不知道哪裡有在討論呢?
最好是中文的.呵
不行!
问个问题:专人专用是不是既能省时间,又比较不容易出现四不像的副作用呢 ?
因为感觉是用同一个 src 去拟合多组 dst ,感觉比较不会出现不像原脸的状况
不好意思,我是剛接觸的新手,也沒有這類的基礎,我試著嘗試製作了一個,軟體本身附帶的兩個影片(鋼鐵人與???)檔合成。跑了一次流程,成功替換臉部。
1.想問是只要有一個200萬的優質的H128模型,只要套用上,其他的運算就會相對快很多嗎?
那我該怎麼訓練一個優質模型?不太明白模型是甚麼。
2.我試著製作軟體本身教學影片,所留下的檔案那些要刪除與保留?
因為想在換兩個新個影片再嘗試一次。
麻煩您替我解惑,先謝謝了。
可以加速, 如果有一个比较好的模型,只你只需要直接换视频继续跑就好了。