Fakeapp 入门教程(2):使用篇!
Fakeapp 已经是一个比较老的软件,问题比较多,遇到了也不太好排查,软件已经停更很久,推荐使用更新,更强的DeepFaceLab!
============================================
Fakeapp软件的使用主要分成了三个步骤, 使用之前请确保你的电脑配置还可以,推荐配置是:一张显存大于4G的N卡。Fakeapp是有支持CPU选项,但是用CPU跑非常慢。
- 获取脸部图片
- 训练模型
- 生成视频
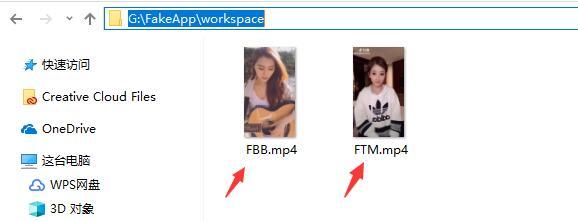
在开始之前你需要先准备两个视频,一个是A视频,一个是B视频,换脸软件可以把B的脸换到A上面。这里加上A视频是FBB(范冰冰),B视频是FTM(冯莫提)。这两个视频放在一个叫workspace的目录里面。下面的路径都为相对G:\FakeApp\workspace\的路径,路径并没有特殊要求,你可以更具自己的情况来选择。
下面就配合图片详细解说下如何操作。
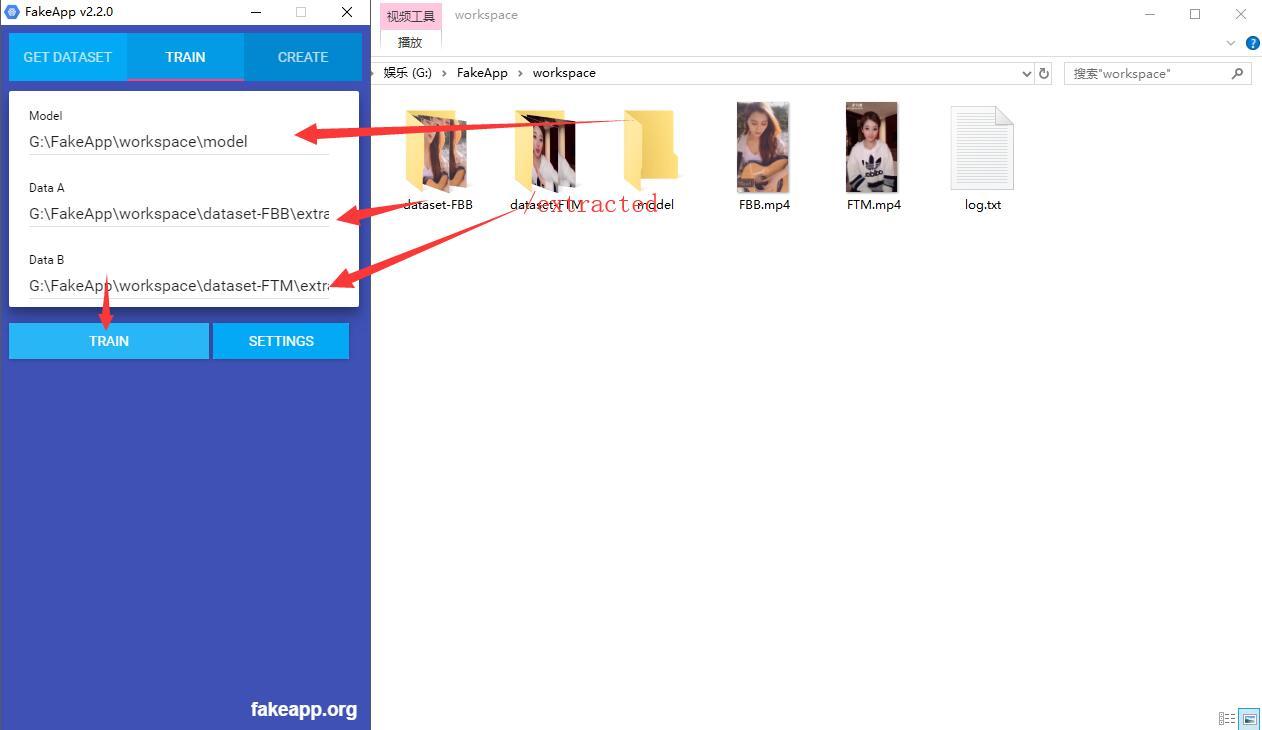
1.获取脸部图片
选中GET DATESET 出现如下界面。
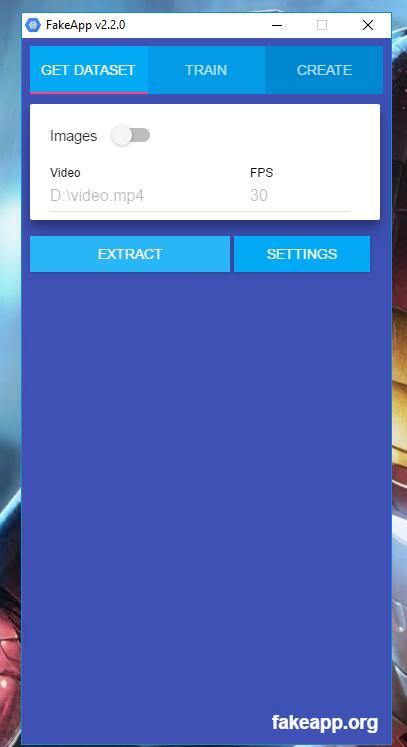
这一步的目的是讲视频分割成图片,然后从图片中提取脸部。
这个环节只需要填写两个地方,一个是Vidoe视频路径,一个是帧率FPS,默认为30.
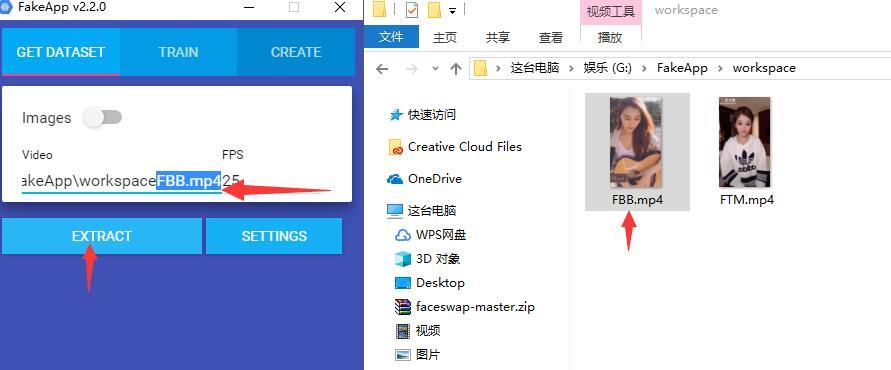
因为我们有两个视频,所以需要分两次次来。.
先在Video中输入G:\FakeApp\workspace\FBB.mp4 ,这个路径不一定是这个样子要更具你的实际情况来。 帧率可以通过视频文件右键属性进行查看,一般是30,24之类。
输入完成后点击EXTRACT(提取) 开始提取。
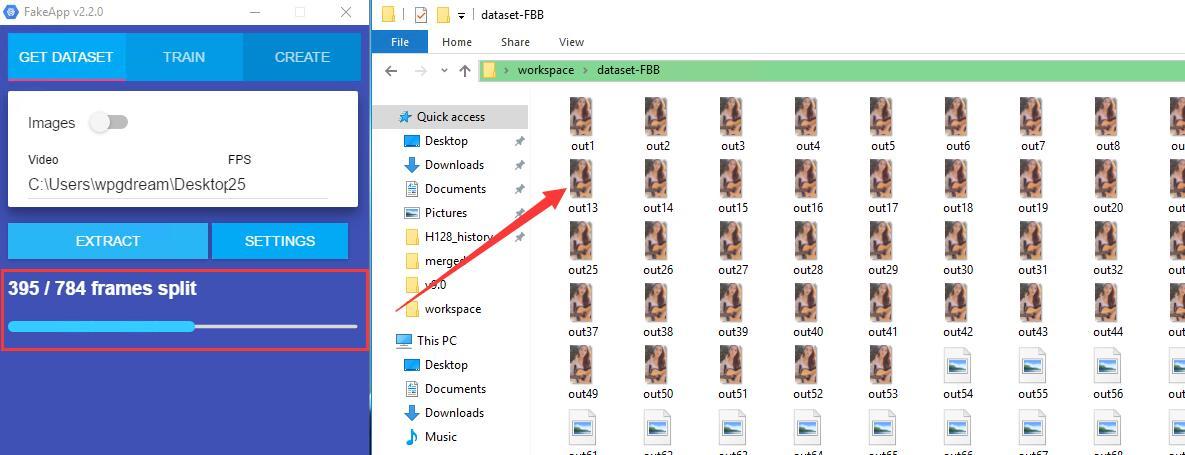
提取分两个阶段,一个是把视频分割成图片,如上图。 一个是把图片中的人脸提取出来保存成新的图片,如下图。
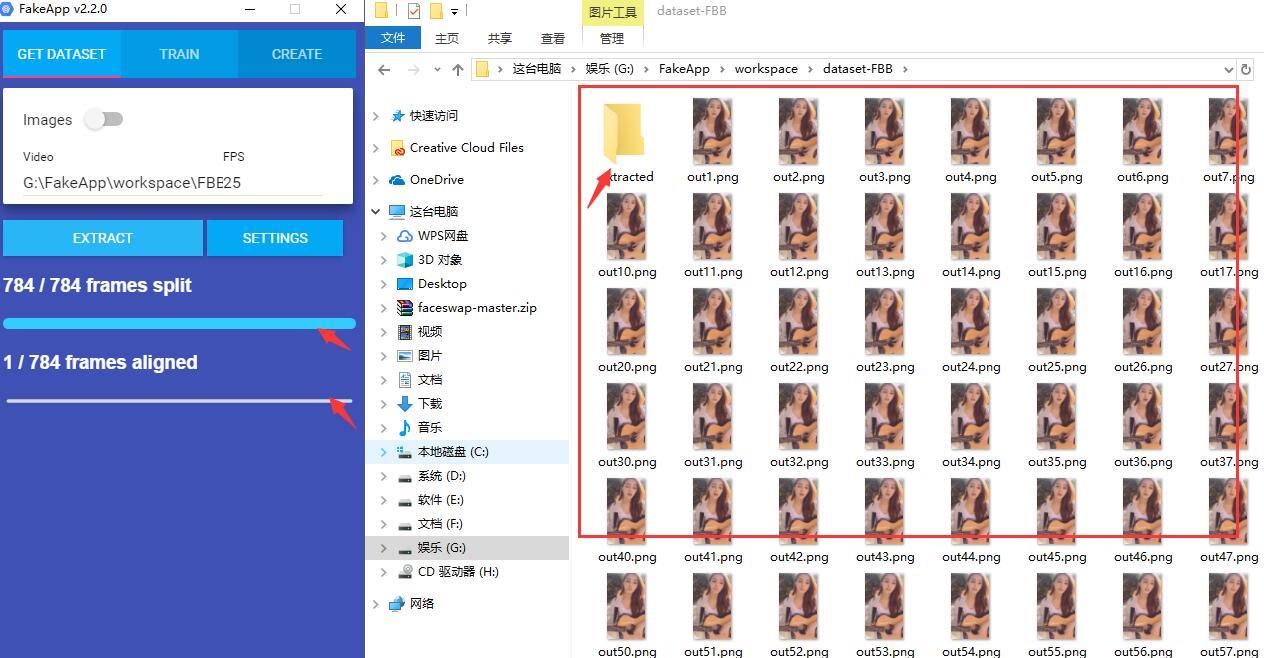
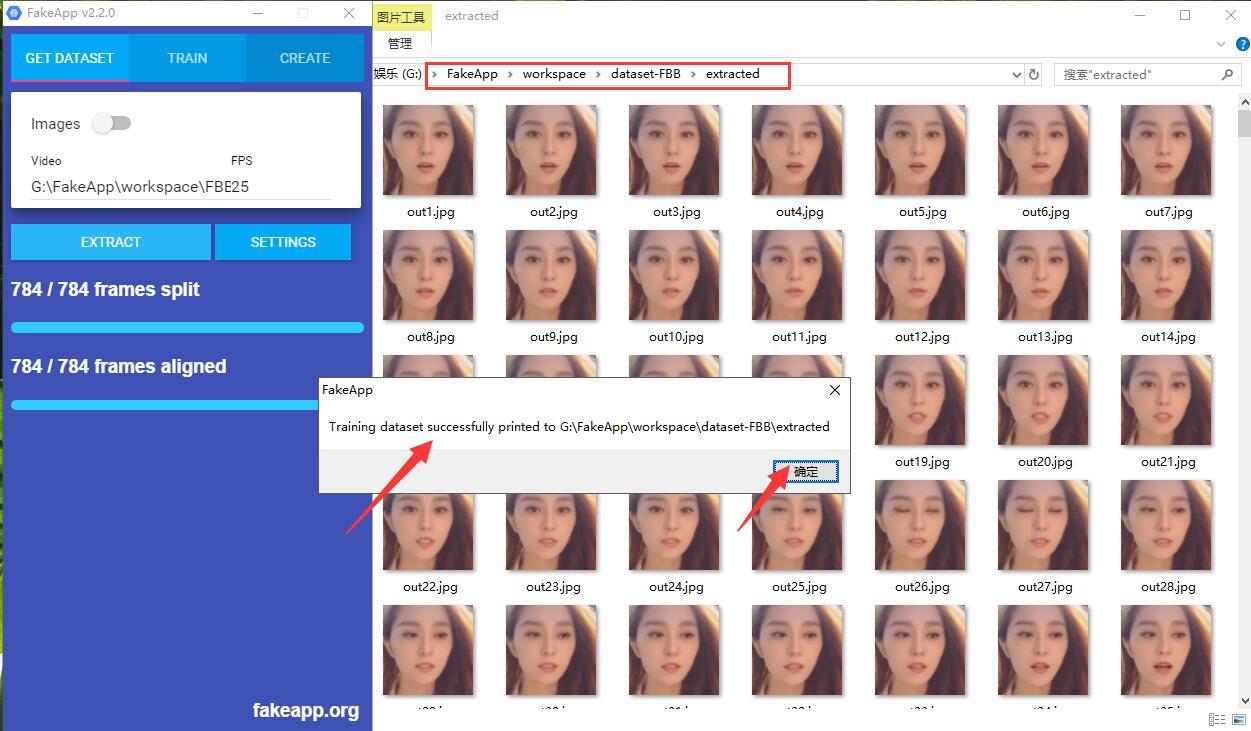
等待进度条结束后跳出Traning dataset successfully 这个提示窗口就证明成功了。点击OK关闭提示窗口。
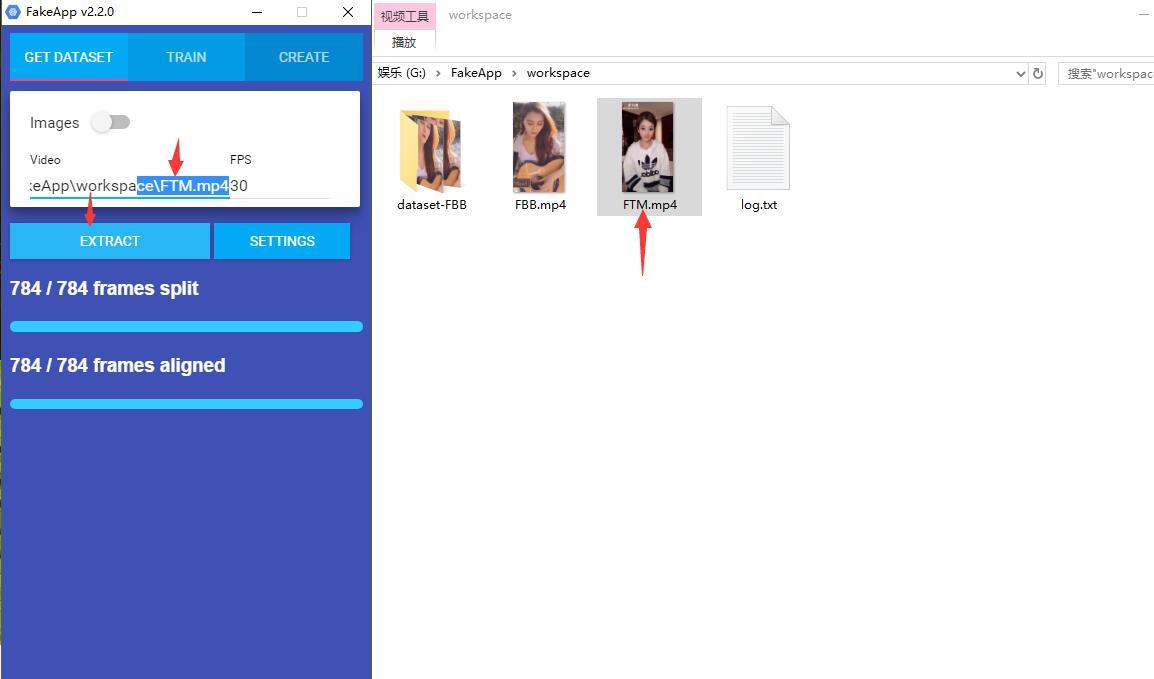
用同样的方式操作FTM.mp4
Video中输入G:\FakeApp\workspace\FTM.mp4 ,这个路径不一定是这个样子要更具你的实际情况来。同样需要输入帧率。
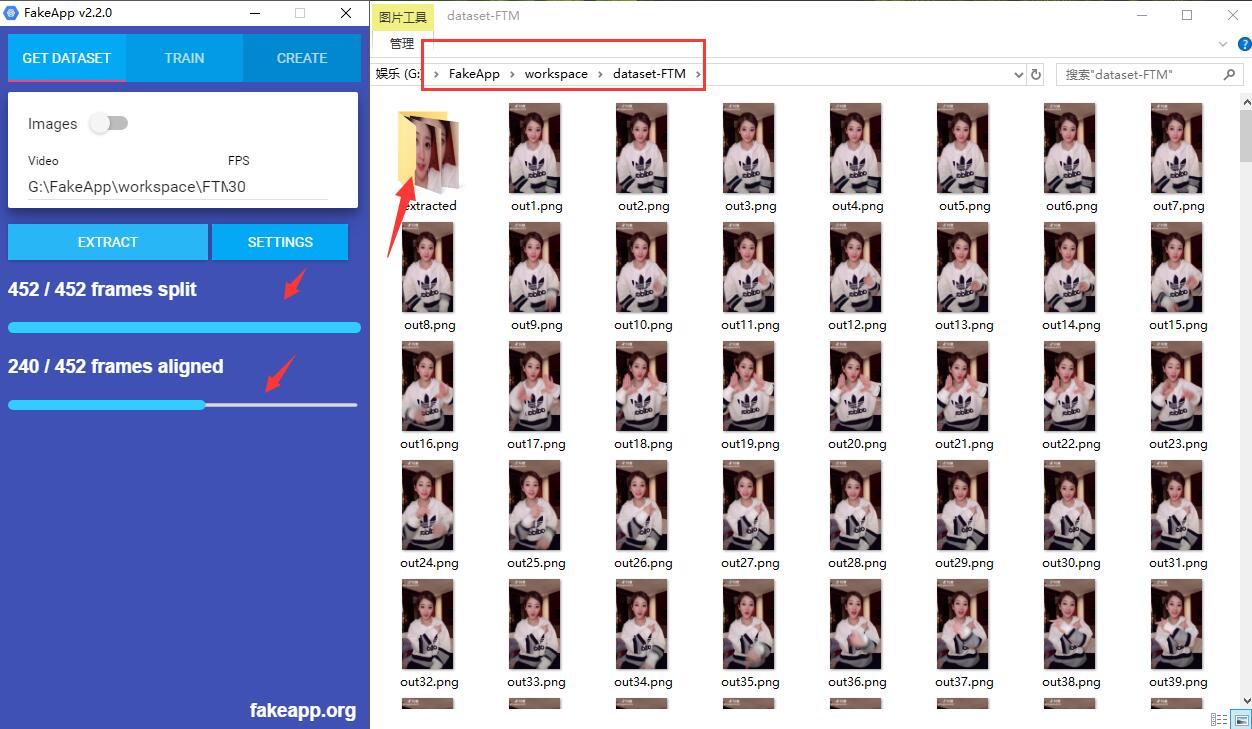
这两个过程完全是一样的,截图如下,就不多解释了。

2.训练模型
模型是很重要的一个东西,也是一个极其消耗时间的东西。训练模型对配置的要求也是比较高。
训练界面主要是上个输入框
Model : 模型的保存路径 (….\workspace\Model)
Data A: 被换的人脸(….\workspace\dataset_FBB\extracted)
Date B: 拿去换的人脸(…..workspace\dataset_FTM\extracted)
….代表你自己的路径。
输入路径之后,点击TRAIN开始训练。稍等片刻下面就会显示Loss A:xxxx ,LossB:xxxx 。 同时Model 目录下除了四个文件。同时还会跳出一个有很多脸的预览窗口。
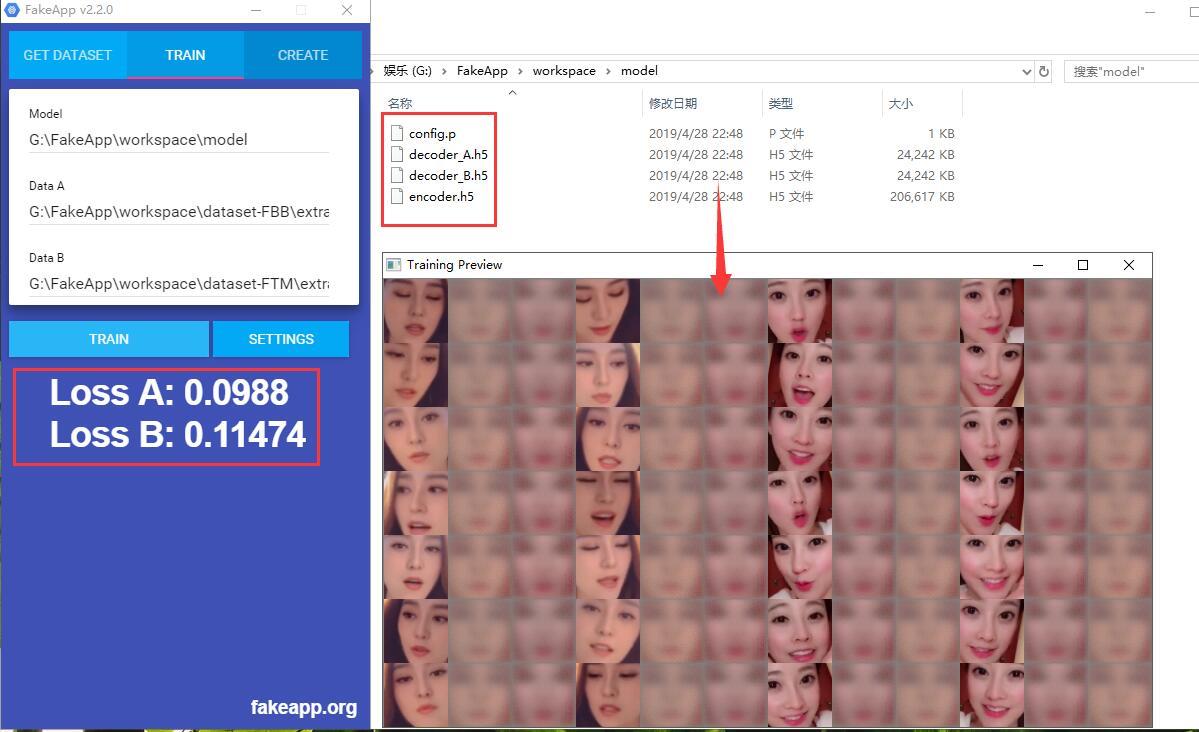
这一个环节是非常耗时间的,一般需要几天时间。软件不会自动停止,你不想训练模型的时候可以手动关闭。下次开启会继续训练。 手动关闭的方法为,鼠标移动到预览窗口,然后按Q结束。
判断这个阶段是否完成了,可以通过两个指标去看。
- Loss A,Loss B 数字越来越像,小到了0.02左右,就差不多了
- 人脸预览图越来越清晰,第二列第三列和第一列一样清晰,就证明差不多了。
训练结束后,即可开始生成视频。
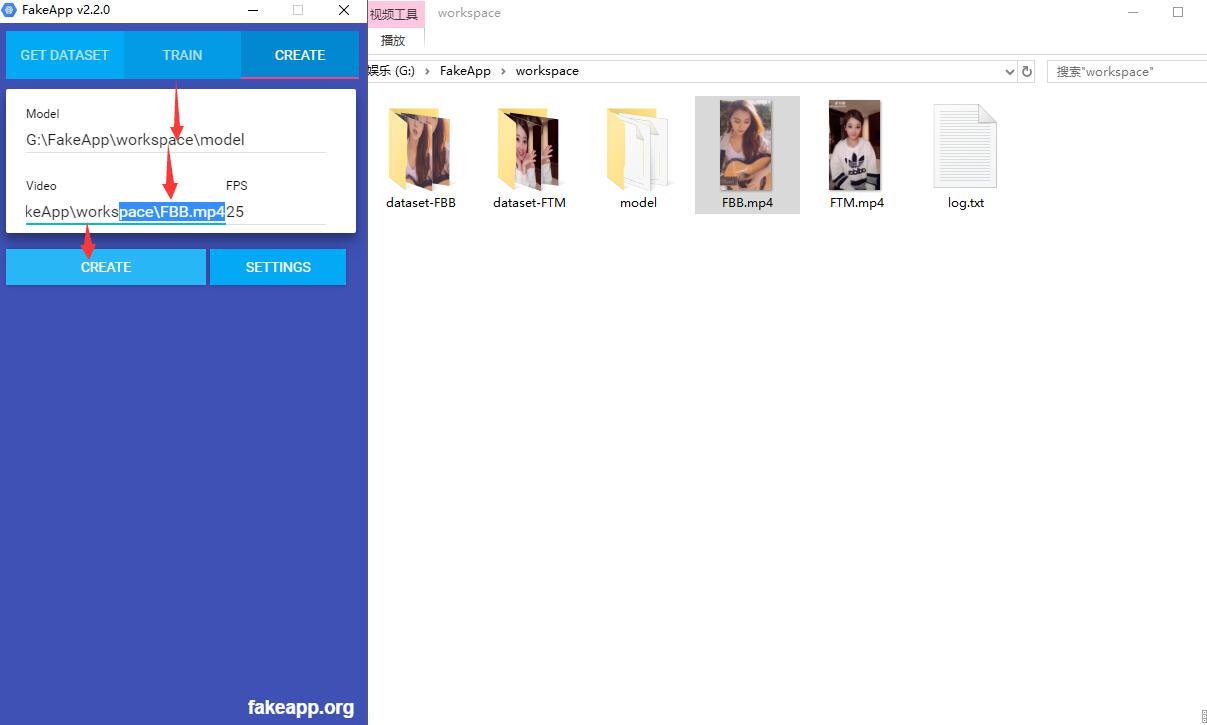
生成视频的过程也是细分了好几个步骤。
首先,你需要输入Model 路径(…\workspace\Model )。Video路径(…\workspace\FTM.mp4) FPS(30)
然后,点击Create。
然后程序自动开始,处理过程可分成4个阶段。
- 生成图片
- 截取脸部
- 合成图片
- 合成视频
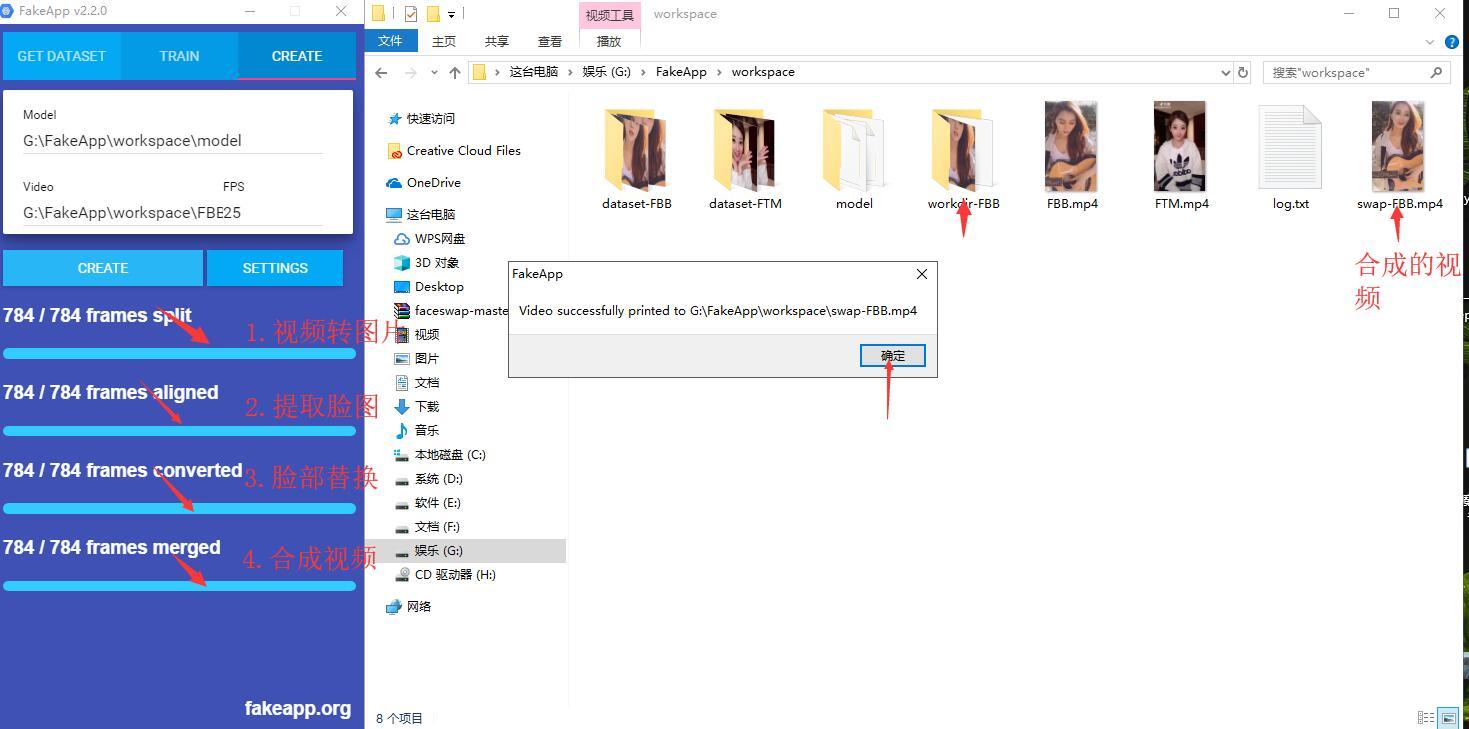
上面四个步骤是软件自动运行,运行结束之后就可以看到一个叫swap-FTM的视频了。这就是换脸后的视频。
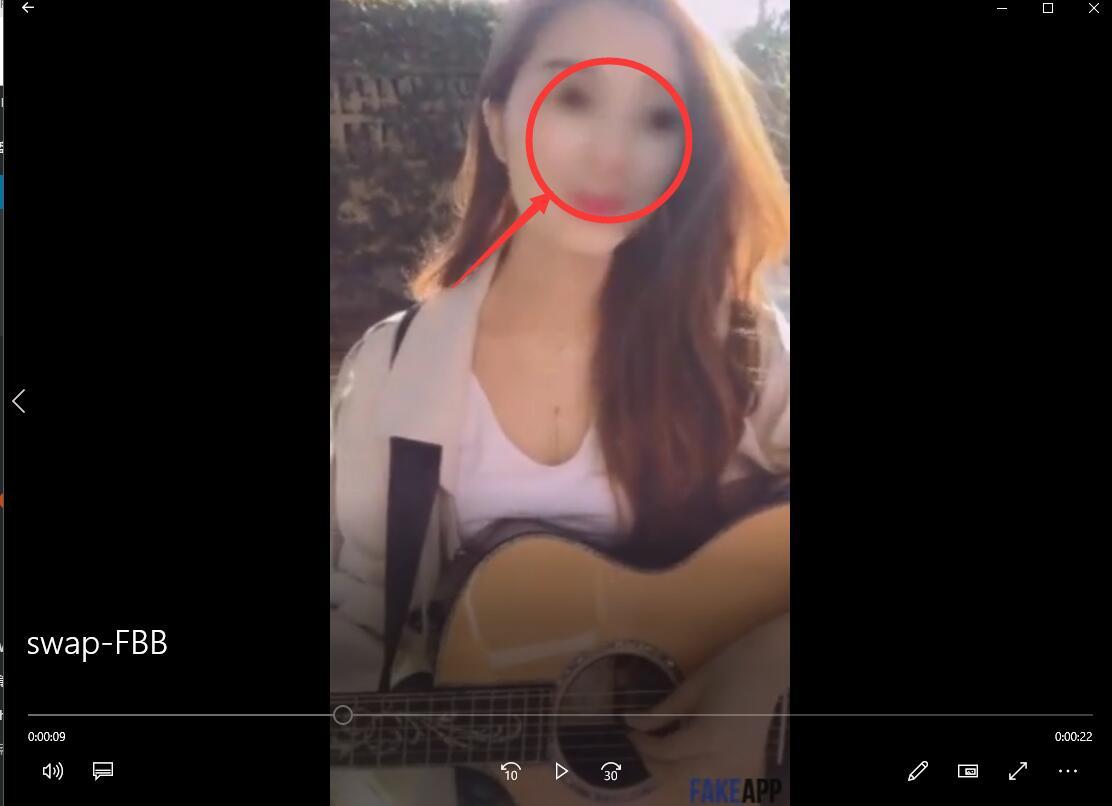
因为我训练时间非常短,所以这个脸是非常模糊的,几乎看不起是谁。如果你训练的时间够长,这里就会非常清晰了。
Fakeapp系列教程
申明:图文均由deepfakes 中文网原创,转发请注明出处,谢谢!

DeepFaceLab:快让rtx30系列的提取速度翻倍吧!!!
GTX 1060 3GB 如何使用DeepFaceLab,能跑么?

为什么切身子,不切脸
不知道为啥,软件我也没有装错,配置也挺高的,内存还是500G的
内存500G ? 还是硬盘500G?
内存一般是4G,8G,16G,500G没听过,或者我孤陋寡闻了! 而且这里需要的是显存,显卡的内存,一般来说需要大于4G !
不知道这样说你明白不?
那如果苹果系统能用不
不支持!
环境安装好了么?
显卡是什么?
内存是4.00GB64位系统
要看显存,就是显卡自带的内存!这个最好是大于等于4GB
这是啥问题,有人物,没脸蛋
undefilinedtotal:784file“align-face·py”line 136,in main
中文路径不行
您好,为什么没有提取脸部图片,只提取了视频的
有错误提示么? 我遇到这个情况是因为软件没装好,按照教程的操作来应该没有问题。 实在搞不定可以加群私聊群主。
那个log文档显示“undefined”
早上开机重新打开软件,范冰冰那个提取了全身和脸部图片,到冯提莫那个又不行了,提不出脸部的图片
QQ群号多少
2019-06-11 23:20:11> Unhandled exception: System.AggregateException: 发生一个或多个错误。 —> System.Net.WebException: 远程服务器返回错误: (403) 已禁止。
在 System.Net.HttpWebRequest.EndGetResponse(IAsyncResult asyncResult)
在 System.Net.WebClient.GetWebResponse(WebRequest request, IAsyncResult result)
在 System.Net.WebClient.DownloadBitsResponseCallback(IAsyncResult result)
— 引发异常的上一位置中堆栈跟踪的末尾 —
在 System.Runtime.CompilerServices.TaskAwaiter.ThrowForNonSuccess(Task task)
在 System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
在 Squirrel.Utility.d__43`1.MoveNext()
这个错误回复是什么问题?我的卡是rtx2060 内存16g
QQ号是多少啊
726684484
搜索不到这个QQ号
这是群号!
进群需要被邀请,怎么进来呢
我的电脑类型64位操作系统,显示适配器,NVISIAGeForce9400M,哪个比较适合用
能带动吗
你这个卡显存很低吧! 是512M 还是1G ? 你这个设置里面把GPU改成CPU吧,或者直接用DeepFaceLabOpenCL版本吧!
我也有一樣的問題,extracted資料夾裡面沒有臉部提取的圖片
可是從影片中提取圖片沒有問題
这是一个非常常见的问题!确认下安装是否完全正确,版本号等,还有如果显卡不行换cpu
路径不要中文就行了
楼主请问A卡是用不了吗?无论GPU或是CPU都切不了图
undefined File “site-packages\PyInstaller\loader\pyiboot01_bootstrap.py”, line 174, in __init__
对的,Fakeapp不支持AMD卡,只支持N卡
刚刚点开始培训培训就结束了,这是什么问题
我知道为什么了 不能切脸了不能用中文路径
电脑类型64位操作系统,显卡Intel(R) HD Graphics 1885 MB
集成显卡玩不转啊!
请问发生这个错误可能是什么原因呢?
undefined File “align_faces.py”, line 33, in main
File “face_alignment\api.py”, line 87, in __init__
Fakeapp错误比较难定位,要不出错,请做到两点:1. 根据本站的安装过程来,一步都不能含糊,版本号必须一一对应。2.确定你有独立的N卡,显存最好是4G以上。
请问楼主,fakeapp可以训练多少张图片?我找了两个视频,分别分解后一共有40000多张头像,点击训练会报错,查找网上的解答说是两个视频分解出来的头像一共不能超过3000张。我从两个文件夹中分别挑了1500张,最后合计3000张,开始训练,结果可以运行了。训练了两天,导出后效果还不是很好。而且如果只能训练3000张的话,那假设我的视频文件是25帧的,那1500张不是只能是60秒的视频?还是有其他办法可以训练更多的图片?
为什么导不出视频,最后一步换脸换好后照片不能转成视频?
log文件里最后几行有error信息:
[image2 demuxer @ 000001aaf31eb6c0] Unable to parse option value “” as video rate
[image2 demuxer @ 000001aaf31eb6c0] Error setting option framerate to value .
E:\Fakeapp\workspace\workdir-FBB\merged\out%d.png: Invalid argument
从提示来看,是帧率设置问题,你是不是没有设置帧率?
怎么设置码率?
不好意思,前面我打错了,是帧率。 填写在FPS的地方! 文件右键属性可以查看视频帧率。
date B 只有 照片可以么?
完全可以,只要你有足够,连续而且符合格式的图片,同时也要涵盖样本动作的多样性
怎么感觉留言的人都是外行
不懂就问啊,我也留个言,我在提取时有个an error 什么什么的,怎么解决?
怎么换图片的脸
undefinedUsing GPU0 for processing
2019-07-16 23:49:03.2019-07-16 23:49:03.563657: I C:\tf_jenkins\workspace\rel-win\M\windowsate(GHz): 1.83
pciBusID: 0000:01:00.0
totalMemory: 6.00GiB freeMemory: 4.89GiB
2019-07-16 23:49:03.564312: I C:\tf_e: 0, name: GeForce RTX 2060, pci bus id: 0000:01:00.0, compute capability: 7.5)
Traceback (most recent call last):
File “execute.py”, line 69, in
File “train.py”, line 39, in main
File “utils.py”, line 6, in get_image_paths
FileNotFoundError: [WinError 3] �t�Χ䤣����w����|�C: ‘D:\\fakeapp video\\AAA.mp4\\extracted’
[968] Failed to execute script execute
這個報錯是甚麼意思 能解答下麼 謝謝了
错误提示文件路径有问题。 你把目录名改成英文,并不要有特殊符号,空格也不要。试试看。
還是一樣呢….. log裡面寫得一模一樣 這是甚麼狀況
为什么生成的视频没有声音呢
fakeapp合成的视频就是没有音轨的,需要自己用视频剪辑软件添加。Deepfacelab合成的默认自带声音。
为什么在训练没有显示loss值
等等
我用的h128模型,为什么素材拉进去了,点击切脸,出现程序缺少必要的文件,为什么
不要重复发那么多!
有点不明白,他显示程序缺少必要的文件
你好,请问有DeepNude的下载地址吗?
这个不是本站主题,^_^!
为什么我选的是Gpu 但训练时, 只有cpu在工作。rtx2070.是我的显卡类型不行吗,一定要专业卡吗?
你显卡没问题的,还可以的。 推荐使用DeepFaceLab
不裁切怎么回事但是提示成功了
Heya! I’m at work browsing your blog from my new iphone! Just wanted to say I love reading your blog and look forward to all your posts! Carry on the great work!
请问,我拿Fakeapp训练了DF模型,怎么才能把这个模型给我的DeepFaceLab用?难道要重新练?已经花了好多时间了啊。
这个两个不通用的,还有我记得Fakeapp应该是H64结构。
为什么只学习了几个小时就很清晰了哈哈哈,还只是1060 6G的
那不是挺好的!不过每个人对清晰的标准不一样! 一般来说几个小时是不够滴,十天半个月很平常。
为何第一步没有问题,第二部training一开始就卡住然后显示有error就不动了?
为什么我什么都做好了,到最后create的时候,在完成split, align, convert,之后到了第四步合并就一直出错呢???
弹出窗口说:An error has occurred in the creation process.
log的最后几行是:
[image2 demuxer @ 000002501339b0c0] Unable to parse option value “” as video rate
[image2 demuxer @ 000002501339b0c0] Error setting option framerate to value .
D:\workspace\workdir-dan\merged\out%d.png: Invalid argument
原来是FPS没有输入。。搞定了
哈哈,只要按步骤来,注意细节,就不会出错!
請問不能截臉 出現錯誤提示
undefined__main__.PyInstallerImportError: Failed to load dynlib/dll ‘cudart64_90.dll’. Most probably this dynlib/dll was not found when the application was frozen.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “execute.py”, line 1, in
是甚麼問題?
环境安装有问题!
請問 錯誤提示
undefined File “site-packages\PyInstaller\loader\pyiboot01_bootstrap.py”, line 174, in __init__
__main__.PyInstallerImportError:
是甚麼問題
undefined File “align_faces.py”, line 7, in
File “C:\Users\CTH\AppData\Local\FakeApp\app-2.2.0\resources\api\torch\__init__.py”, line 76, in
from torch._C import *
ImportError: DLL load failed: �䤣����w���ҲաC
[5384] Failed to execute script execute
我和这个一样,解决了吗
请问楼主 安装都照做了 再提取的的步骤 只能提取身体 不能提取脸部
LOG报错
undefined File “d:\anaconda\envs\fakeapp\lib\site-packages\PyInstaller\loader\pyimod03_importers.py”, line 631, in exec_module
File “align_faces.py”, line 7, in
File “C:\Users\CTH\AppData\Local\FakeApp\app-2.2.0\resources\api\torch\__init__.py”, line 76, in
from torch._C import *
ImportError: DLL load failed: �䤣����w���ҲաC
[9156] Failed to execute script execute
这是什么意思?
缺少文件
請問缺少了什麼文件…重新安裝了一遍還是一樣
請問缺少了什麼文件…..我重新裝好幾次都這樣
请问 undefinedUsing GPU0 for processing
File “train.py”, line 41, in main
Traceback (most recent call last):
File “execute.py”, line 69, in
File “utils.py”, line 14, in load_images
MemoryError
[9172] Failed to execute script execute
Traceback (most recent call last):
File “execute.py”, line 69, in
File “train.py”, line 41, in main
MemoryError
[7508] Failed to execute script execute
是什么意思呢 连续试了两次都是这样 感谢
内存错误,是不是你的显存比较小?
今天又实验了新的视频,又可以了,麻烦请问下是不是视频清晰度不高的话 就识别不出脸部,因为我拿一个标清的就是识别不出来,然后这次我用了一个4K视频 就搞定了 不好意思 新手 所以有很多问题 麻烦了
8G物理内存带不动的淡淡忧伤
undefinedffmpeg version git-2017-12-29-0c78b6a Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 7.2.0 (GCC)
configuration: –enable-gpl –enable-version3 –enable-sdl2 –enable-bzlib –enable-fontconfig –enable-gnutls –enable-iconv –enable-libass –enable-libbluray –enable-libfreetype –enable-libmp3lame –enable-libopencore-amrnb –enable-libopencore-amrwb –enable-libopenjpeg –enable-libopus –enable-libshine –enable-libsnappy –enable-libsoxr –enable-libtheora –enable-libtwolame –enable-libvpx –enable-libwavpack –enable-libwebp –enable-libx264 –enable-libx265 –enable-libxml2 –enable-libzimg –enable-lzma –enable-zlib –enable-gmp –enable-libvidstab –enable-libvorbis –enable-libvo-amrwbenc –enable-libmysofa –enable-libspeex –enable-amf –enable-cuda –enable-cuvid –enable-d3d11va –enable-nvenc –enable-dxva2 –enable-avisynth –enable-libmfx
libavutil 56. 7.100 / 56. 7.100
libavcodec 58. 9.100 / 58. 9.100
libavformat 58. 3.100 / 58. 3.100
libavdevice 58. 0.100 / 58. 0.100
libavfilter 7. 8.100 / 7. 8.100
libswscale 5. 0.101 / 5. 0.101
libswresample 3. 0.101 / 3. 0.101
libpostproc 55. 0.100 / 55. 0.100
[image2 demuxer @ 0000024e92d3b6c0] Unable to parse option value “” as video rate
[image2 demuxer @ 0000024e92d3b6c0] Error setting option framerate to value .
C:\FakeApp\workspace\workdir-2\merged\out%d.png: Invalid argument
undefinedUsing GPU0 for processing
Traceback (most recent call last):
File “execute.py”, line 69, in
File “train.py”, line 40, in main
File “utils.py”, line 6, in get_image_paths
OSError: [WinError 123] �ļ�����Ŀ¼�����������ȷ��: ‘\u202aD:\\pc\\FakeApp\\TEST\\B\\dataset-B\\extracted’
[940] Failed to execute script execute
训练报错,求解
undefined File “align_faces.py”, line 136, in main
File “align_faces.py”, line 103, in iter_face_alignments
请问这是什么意思
undefinedffmpeg version git-2017-12-29-0c78b6a Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 7.2.0 (GCC)
configuration: –enable-gpl –enable-version3 –enable-sdl2 –enable-bzlib –enable-fontconfig –enable-gnutls –enable-iconv –enable-libass –enable-libbluray –enable-libfreetype –enable-libmp3lame –enable-libopencore-amrnb –enable-libopencore-amrwb –enable-libopenjpeg –enable-libopus –enable-libshine –enable-libsnappy –enable-libsoxr –enable-libtheora –enable-libtwolame –enable-libvpx –enable-libwavpack –enable-libwebp –enable-libx264 –enable-libx265 –enable-libxml2 –enable-libzimg –enable-lzma –enable-zlib –enable-gmp –enable-libvidstab –enable-libvorbis –enable-libvo-amrwbenc –enable-libmysofa –enable-libspeex –enable-amf –enable-cuda –enable-cuvid –enable-d3d11va –enable-nvenc –enable-dxva2 –enable-avisynth –enable-libmfx
libavutil 56. 7.100 / 56. 7.100
libavcodec 58. 9.100 / 58. 9.100
libavformat 58. 3.100 / 58. 3.100
libavdevice 58. 0.100 / 58. 0.100
libavfilter 7. 8.100 / 7. 8.100
libswscale 5. 0.101 / 5. 0.101
libswresample 3. 0.101 / 3. 0.101
libpostproc 55. 0.100 / 55. 0.100
[image2 @ 0000026a4639ab00] Could find no file with path ‘D:\fakeapp2.2\workdir-.2\merged\out%d.png’ and index in the range 0-4
D:\fakeapp2.2\workdir-.2\merged\out%d.png: No such file or directory
请问是什么情况呢?卡在合成这一步好久额,都是因为这个问题
这个是路径有问题,或者你把不该删除的删除了。
Training process ended. If you did not end it yourself, an error occurred. Check the end of the log. txt file for details, and feel free to post it on fakeapp. org/forum for help.
训练模型出现这个怎么办
Fake app 的问题比较难排查,主要方向有,1.文件路径有没有中文和特殊符号 2. 显存是否够用,3.视频帧率有没有写对, 4. 文件路径有没有写对。 最后,推荐用DeepFaceLab 。
fakeappでGET DATASET⇒EXTRACTを実行すると終了後にエラーメッセージが出てきます。「dateset-XX」フォルダの中に動画の画像がpngで出力されています。 そのフォルダ中に「extracted-XX」フォルダが作成されるはずなのですが、作成されません。顔画像が抽出されたjpgファイルが書きだされないのです。どなたかfakeappに詳しい方、対策をご存じの方、教えて頂けませんでしょうか?宜しくお願い致します。
DeepFaceLabを使用することをお勧めしますが、日本語がわかりません~~
你好,我的显卡为NVIDIA GeForce GTX 960,4G显存,请问有没有这个显存能跑得动的模型呢?
提取过程中故障,log文件显示
undefined File “ctypes\__init__.py”, line 348, in __init__
OSError:
这是什么故障
路径看一下对不对。还有文件夹有没有中文名,特色符号等。
An error has occurred in the creation process.Check the end of the log.txt file for the details,and feel free to post in on fakeapp.org/form for help
他出現這段訊息要怎樣處理
你去日志文件 log.txt
undefinedUsing GPU0 for processing
這怎樣處理
undefined__main__.PyInstallerImportError: Failed to load dynlib/dll ‘cudart64_90.dll’. Most probably this dynlib/dll was not found when the application was frozen.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “execute.py”, line 1, in
要怎樣辦
麻烦问下为什么会这样呀
undefinedReading config file from D:\fakeapp\video\Model\config.p
Using GPU0 for processing
I C:\tf_jenkins\workspace\rel-win\M\win2019-09-23 19:50:01.209426: Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
nd device 0 with properties:
name: GeForce GTX 1660 Ti major: 7 minor: 5 memoryClockRate(GHz): 1.59
pciBusID: 0000:01:00.0
totalMemory: 6.00GiB freeMemory: 4.90GiB
2019-09-23 19:50:01.395179: I C:\tf_jenkins\workspace\rel-win\M\windows-gpu\PY\36\tensorflow\core\common_runtime\gpu\gpu_device.cc:1195] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: GeForce GTX 1660 Ti, pci bus id: 0000:01:00.0, compute capability: 7.5)
THCudaCheck FAIL file=d:\pytorch\pytorch\torch\lib\thc\generic/THCStorage.cu line=58 error=2 : out of memory
File “align_faces.py”, line 33, in main
File “face_alignment\api.py”, line 122, in __init__
File “C:\Users\Dolores\AppData\Local\FakeApp\app-2.2.0\resources\api\torch\nn\modules\module.py”, line 216, in cuda
return self._apply(lambda t: t.cuda(device))
File “C:\Users\Dolores\AppData\Local\FakeApp\app-2.2.0\resources\api\torch\nn\modules\module.py”, line 146, in _apply
module._apply(fn)
File “C:\Users\Dolores\AppData\Local\FakeApp\app-2.2.0\resources\api\torch\nn\modules\module.py”, line 146, in _apply
module._apply(fn)
File “C:\Users\Dolores\AppData\Local\FakeApp\app-2.2.0\resources\api\torch\nn\modules\module.py”, line 146, in _apply
module._apply(fn)
File “C:\Users\Dolores\AppData\Local\FakeApp\app-2.2.0\resources\api\torch\nn\modules\module.py”, line 152, in _apply
param.data = fn(param.data)
File “C:\Users\Dolores\AppData\Local\FakeApp\app-2.2.0\resources\api\torch\nn\modules\module.py”, line 216, in
ptxas fatal : Memory allocation failure
ptxas fatal : Memory allocation failure
ptxas fatal : Memory allocation failure
THCudaCheck FAIL file=d:\pytorch\pytorch\torch\lib\thc\generic/THCStorage.cu line=58 error=33 : invalid resource handle
File “align_faces.py”, line 33, in m
請問我已經提取了兩組照片,在train階段開始的時候 lossA跟 lossB都沒有數值顯示,也沒有出現預覽視窗,但工作管理員有看到cpu跟ram都有跑滿,最後會自己停止而且model裡也沒有圖片,請問我該如何解決?
cpu:i5 3470
gpu:1060 3g
ram:12G 1600
请问 对视频的长度有要求吗?
没有,但是不要太长,如果太长可以考虑分段处理。
請問這是什麼問題
undefinedffmpeg version git-2017-12-29-0c78b6a Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 7.2.0 (GCC)
configuration: –enable-gpl –enable-version3 –enable-sdl2 –enable-bzlib –enable-fontconfig –enable-gnutls –enable-iconv –enable-libass –enable-libbluray –enable-libfreetype –enable-libmp3lame –enable-libopencore-amrnb –enable-libopencore-amrwb –enable-libopenjpeg –enable-libopus –enable-libshine –enable-libsnappy –enable-libsoxr –enable-libtheora –enable-libtwolame –enable-libvpx –enable-libwavpack –enable-libwebp –enable-libx264 –enable-libx265 –enable-libxml2 –enable-libzimg –enable-lzma –enable-zlib –enable-gmp –enable-libvidstab –enable-libvorbis –enable-libvo-amrwbenc –enable-libmysofa –enable-libspeex –enable-amf –enable-cuda –enable-cuvid –enable-d3d11va –enable-nvenc –enable-dxva2 –enable-avisynth –enable-libmfx
libavutil 56. 7.100 / 56. 7.100
libavcodec 58. 9.100 / 58. 9.100
libavformat 58. 3.100 / 58. 3.100
libavdevice 58. 0.100 / 58. 0.100
libavfilter 7. 8.100 / 7. 8.100
libswscale 5. 0.101 / 5. 0.101
libswresample 3. 0.101 / 3. 0.101
libpostproc 55. 0.100 / 55. 0.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from ‘E:\loona25.mp4’:
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1iso6mp41
title : 이달의소녀탐구 #25 (LOONA TV #25)
encoder : Lavf58.29.100
Duration: 00:00:28.09, start: 0.000000, bitrate: 949 kb/s
Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p(tv, bt709), 854×480 [SAR 1:1 DAR 427:240], 816 kb/s, 22.92 fps, 23.98 tbr, 90k tbn, 47.95 tbc (default)
Metadata:
handler_name : VideoHandler
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 129 kb/s (default)
Metadata:
handler_name : SoundHandler
Stream mapping:
Stream #0:0 -> #0:0 (h264 (native) -> png (native))
Press [q] to stop, [?] for help
Output #0, image2, to ‘E:\workdir-loona25\out%d.png’:
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1iso6mp41
title : 이달의소녀탐구 #25 (LOONA TV #25)
encoder : Lavf58.3.100
Stream #0:0(und): Video: png, rgb24, 854×480 [SAR 1:1 DAR 427:240], q=2-31, 200 kb/s, 25 fps, 25 tbn, 25 tbc (default)
Metadata:
handler_name : VideoHandler
encoder : Lavc58.9.100 png
你好 群加不了了,能加一下群交流下么?
請問我打開log文件顯示:
undefinedUsing GPU0 for processing
Traceback (most recent call last):
File “execute.py”, line 69, in
File “train.py”, line 42, in main
File “utils.py”, line 15, in load_images
ValueError: could not broadcast input array from shape (155,101,3) into shape (208,221,3)
[8396] Failed to execute script execute
該怎麼處理?
另外我想問一下deepfakeapp的cudnn是用7.0.5還是7.5.0?
第一篇文章是說7.0.5可是cudnn的文章說7.5.0
提取脸部提取不了,提示:undefined File “align_faces.py”, line 136, in main
File “align_faces.py”, line 103, in iter_face_alignments。请问楼主这是啥情况。
Hey bro, 没有显卡啊,近百核的CPU,256G内存能玩吗
能玩玩,但是可能比不上一张显卡。
想請問一個問題,我在Train的那一個步驟,如圖下就就不動了,想請問解決方法,感謝!
https://uploads.disquscdn.com/images/e82b587aedf354748e72dc6983d3daa69795f9828a7b213f8ca63fc124386dbe.png
显示OOM,内存不够。
培訓過程結束。 如果您自己沒有結束,則會發生錯誤。 檢查log.tt文件的末尾以獲取詳細信息,並隨時將其發佈在fakeapp.org/forum上以尋求幫助。
為什麼我在Get Dataset那邊選擇 images 一直會出錯誤呢?
每次跑到 1/7 images extracted時就出現error了.
“An error has occurred in the creation process. Check the end of the log.txt file for detail.”
但是他的log file並沒有文件裡面 也找不到,Images directory沒有錯.
undefined File “execute.py”, line 2, in
File “d:\anaconda\envs\fakeapp\lib\site-packages\PyInstaller\loader\pyimod03_importers.py”, line 631, in exec_module
File “align_faces.py”, line 7, in
File “C:\Users\USER\AppData\Local\FakeApp\app-2.2.0\resources\api\torch\__init__.py”, line 76, in
from torch._C import *
ImportError: DLL load failed: �䤣����w���ҲաC
[10816] Failed to execute script execute
請問是缺少了什麼文件….重裝好幾次都一樣
老哥,刚刚发现你的网站被墙了,我觉得广电总局就他娘的一堆傻X,整天打着净网的旗号,结果,2020年了,封了一堆正规资源、墙了一批正规网站,偏偏放过一些黄色资源的网站。
人在屋檐下,没地方说理!!
不知道站長還有沒有在,可以幫忙看看嗎?
undefinedUsing GPU0 for processing
Traceback (most recent call last):
File “execute.py”, line 69, in
File “train.py”, line 39, in main
File “utils.py”, line 6, in get_image_paths
FileNotFoundError: [WinError 3] �t�Χ䤣����w����|�C: ‘C:\\Users\\supwo\\Desktop\\1\\3\\extracted’
[12428] Failed to execute script execute
看起来是路径问题,把文件名路径名中的中文特殊符号去掉试试。
感謝教學,很受用。
我想問個問題,如果原影片解析出的人臉,有不想替換的,是否就直接刪除掉就可以?
恩
点了train以后model里面没有任何反应怎么办
请问大神,这个会有调整肤色的解决办法么?
还是说我的模型训练时间还不够呢?
使用fakeapp2.2,在训练结束时按Q后,一般会有弹框出现吗(弹框内容意思是,进程结束,不是手动则是产生错误)。最后我有输出视频,但没用上model里的信息样,脸都没反应,我训练了好几天
大神,请帮我解答一下,谢谢你
哎,每一次训练都出现错误
记事本上的错误日志是这个:
undefined File “d:\anaconda\envs\fakeapp\lib\site-packages\PyInstaller\loader\pyimod03_importers.py”, line 631, in exec_module
File “merge_faces.py”, line 8, in
File “d:\anaconda\envs\fakeapp\lib\site-packages\PyInstaller\loader\pyimod03_importers.py”, line 631, in exec_module
undefined File “d:\anaconda\envs\fakeapp\lib\site-packages\PyInstaller\loader\pyimod03_importers.py”, line 631, in exec_module
这个怎么办啊??切不出脸
undefined File “ctypes\__init__.py”, line 348, in __init__
File “site-packages\PyInstaller\loader\pyiboot01_bootstrap.py”, line 174, in __init__
__main__.PyInstallerImportError: Failed to load dynlib/dll ‘cudart64_90.dll’. Most probably this dynlib/dll was not found when the application was frozen.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “execute.py”, line 1, in
File “d:\anaconda\envs\fakeapp\lib\site-packages\PyInstaller\loader\pyimod03_importers.py”, line 631, in exec_module
File “merge_faces.py”, line 8, in
File “d:\anaconda\envs\fakeapp\lib\site-packages\PyInstaller\loader\pyimod03_importers.py”, line 631, in exec_module
File “d:\anaconda\envs\fakeapp\lib\site-packages\PyInstaller\loader\pyimod03_importers.py”, line 631, in exec_module
File “d:\anaconda\envs\fakeapp\lib\site-packages\PyInstaller\loader\pyimod03_importers.py”, line 631, in exec_module
ImportError: Could not find ‘cudart64_90.dll’. TensorFlow requires that this DLL be installed in a directory that is named in your %PATH% environment variable. Download and install CUDA 9.0 from this URL: https://developer.nvidia.com/cuda-toolkit
[19468] Failed to execute script execute
log.txt是这样 显示有错 请问是哪里?
推荐使用DeepFaceLab
undefined File “ctypes\__init__.py”, line 348, in __init__
error
My system config: Quad core with 4gb Nvidea graphic card and 8gb ram.
错了,应该是
undefinedTraceback (most recent call last):
File “execute.py”, line 1, in
File “d:\anaconda\envs\fakeapp\lib\site-packages\PyInstaller\loader\pyimod03_importers.py”, line 631, in exec_module
File “merge_faces.py”, line 8, in
fakeapp的安装必须要硬件支持,并且严格安装我提供的版本号安装,否则很容易出错。这个软件有点老了,问题也不少,现在基本用Deepfacelab,效果比较好。